
Архитектуры вычислительных систем линии БЭСМ-6 и Эльбрус-2.
Большинство из описанных выше структурных и архитектурных способов увеличения производительности ВС были открыты в 60-х годах и вначале применены на отдельных моделях ЭВМ 2-го и 3-го поколений, потом стали использоваться в ВС высокой производительности и, наконец, после усовершенствования апробирования нашли применение в серийных ЭВМ и ВС различных классов 3-го и 4-го поколений. Это обычный путь внедрения новых технических решений и не только в ЭВМ. Но бывает и так, что появляется машина, в которой сразу и успешно внедрены многие “революционные” технические идеи. Такие машины вместо жизненного цикла (морального старения) в десяток лет выпускаются 20 и более лет и кладут начало новому семейству.
В гражданской авиации такими машинами были ПО-2, ЛИ-2,. (ДС-3), Ил-62; в автомобильной промышленности – первая модель “Фольксваген”; среди ЭВМ – серия 6000 Control Data, семейство IBM-360/370, БЭСМ-6. За созданием таких моделей в вычислительной технике стоят имена выдающихся архитекторов-конструкторов ЭВМ: Сеймура Крея, Дж. Амдала, академика Лебедева – людей не только генерировавших передовые идеи, но и организаторов, создавших вокруг себя коллективы талантливых коллег и последователей.
Рассмотрим более подробно ретроспективу и перспективу развития одной из самых популярных отечественных ЭВМ для научных расчетов – БЭСМ-6. Эта машина была выпущена в 1966 г. и пошла в серию 1967 г. Она была задумана как ЭВМ для расчетов в самых различных областях науки и техники для оснащения ею крупных вычислительных центров. Формально ее относили к ЭВМ 2-го поколения, так как ее элементная база выполнена на дискретных элементах. Но по всем прочим признакам: иерархической системе памяти с постоянной организацией; наличию виртуальной (математической) памяти; большому числу каналов, обслуживающих периферийные устройства и внешнюю память; наличию эффективных операций с плавающей запятой; наличие сверхбыстрого ЗУ, системы индексации команд, системы прерывания; наличию операционной системы и т.д. – БЭСМ-6 являлось вычислительной системой 3-го поколения. В течение нескольких лет она была самой высокопроизводительной ЭВМ в Европе.
Появление БЭСМ-6 не было случайным, но и не являлось последовательным усовершенствованием и развитием предыдущей БЭСМ-4. ЭВМ с быстродействием в несколько сот тысяч операций в секунду над числами, представленными в формате с плавающей запятой, и оперативной памятью в десятки тысяч слов была остро необходима для научных и проектировочных расчетов в авиации, космонавтике, ядерной физике, сложных отраслях машиностроения и т.п.
Для этого было необходимо создать рывок в разработке и выпуске ЭВМ, улучшив как минимум сразу на порядок (!) значения основных параметров ЭВМ моделей БСЭМ-4 и М-222, выпускавшихся для научных расчетов у нас в стране. Причем требовалось сделать не уникальную ЭВМ в нескольких экземплярах, а создать технологичную в производстве и относительно не дорогую ЭВМ для оснащения ею больших ВЦ в институтах АН СССР и в промышленности. Именно такая задача и стояла перед коллективом С.А. Лебедева, и результатом ее успешного решения явилась ЭВМ БЭСМ-6.
Элементная база, специально разработанная для быстродействующих логических устройств БЭСМ-6 основывалась на применении транзисторного парафазного усилителя с диодной логикой на входе. На этой базовой схеме строились логические ячейки И – ИЛИ (вентиль), И – ИЛИ – И, а так же другие, более сложные, но практически укладывающиеся по времени переключения в стандартный такт машины. Частота тактирующих сигналов в БЭСМ-6 принято в 10 МГц.
Каждый тактированный усилитель имеют обратную связь и сохраняет полученный код в течение одного полутакта (50 нс), пока замкнутая его обратная связь. Для долговременного хранения кода предусмотрена включаемая в этом случае вторая обратная связь. Сома по себе тактовая частота 10 МГц еще не обеспечивала производительности в сотни тысяч операций в секунду. Требовались решения архитектурного плана.
Архитектура БЭСМ-6. Длина слова БЭСМ-6 выбрана 48 двоичных разрядов. В это время имелись отечественные и зарубежные машины с длиной слова в 60, 45, 36, 32. Наиболее длинная 60-разрядная слова имели американские высокопроизводительные ЭВМ CDC серии 6000, но они были достаточно уникальными, многопроцессорными, дорогими и выпускались малой серией. В БЭСМ-6 48-разрядное слово позволяло представить число с плавающей запятой с достаточной точностью (40 разрядов на мантиссу) и с большим диапазоном чисел от 2-64 до 2+63.
Структура числового слова в БЭСМ-6:
|
Знак порядка |
Порядок |
Знак мантиссы |
Мантисса |
|
48 |
47 ...... 42 |
41 |
40 ..... 1 |
Нумерация разрядов в слове идет справа налево. Слово может представлять и 48 равноправных двоичных цифр. В слове размещаются две 24-разрядные команды. Чтобы, с одной стороны, иметь достаточный полный набор операций (команд), а с другой – иметь по возможности длинный адрес для прямой адресации ячеек памяти большого объема, используются команды двух типов:
|
i |
0 |
ФА |
КОП 1 |
Короткий адрес |
1-ый тип |
|
|
24 .. 21 |
20 |
19 |
18 .. 13 |
12 ..... 1 |
||
|
i |
1 |
КОП 2 |
Длинный адрес |
2-ой тип |
||
|
24 .. 21 |
20 |
19 ..... 16 |
15 ..... 1 |
|||
i – номер используемого индекс-регистра (от 1 до 15);
20-ый разряд определяет тип команды;
19-ый разряд в командах первого типа определяет способ формирования адреса, им могут быть четыре первых или четыре последних листа.
В системе команд БЭСМ-6 предусмотрено 50 команд, разделяемых на шесть групп: арифметические операции; операции пересылки и логические операции; операции с индекс-регистрами и операции изменения адреса; операции передачи управления; специальные операции; макрокоманды. Код макрокоманды вызывают прерывание, и операционная система передает управление программе с номером данной макрокоманды.
Из уже упомянутых характеристик БЭСМ-6 мы можем отметить: наличие системы индексного преобразования адресов в команде при помощи индексных регистров без затраты дополнительных тактов, наличие системы прерывания, наличие операционной системы, 15-разрядное адресное поле у команд второго типа, превышающее у первых ЭВМ БЭСМ-6 длину адреса ОЗУ.
Ряд необычных схемных решений в арифметическом устройстве (невидимых программисту) обеспечил возможность при такте 10 МГц получить высокое быстродействие выполнения операций: сложение – 1,1 мкс, умножение – 1,9 мкс, деление – 4,9 мкс, прочие операции – 0,5 мкс. Это позволяет оценить среднее быстродействие АУ в 1 млн. оп/с. Но, чтобы использовать это быстродействие АУ, надо обеспечить подачу в него и выведение из него данных с таким же темпом. В этой задаче содержится одно из главных противоречий между высокой скоростью АУ и низкой скоростью записи и считывания данных и команд из устройств памяти.
Как же устраняется это противоречие БЭСМ-6?
Организация памяти в БЭСМ-6. Основная оперативная память (ОЗУ) разделена на 8 блоков, имеющих самостоятельное управление, т.е. организованно расслоение ОЗУ (интерливинг) с глубиной расслоения восемь.
Весь объем ОЗУ разделен на страницы. Одна страница содержит 1024 слова (сокращенно обозначается буквой К – кило). В частности, в 15-разрядном адресе команды старше 5 разрядов определяют номер страницы, а младшие 10 разрядов – положение слова внутри страницы.
Поскольку БЭСМ-6 предназначалась с самого начала для мультипрограммной работы, предусматривалась возможность в каждой программе вести независимо адресацию ОЗУ в так называемы математических адресах. После применения индексной адресации (прибавления содержания индексного регистра к адресной части команды) получается исполнительный математический адрес (и еще не физический).
В структуре машины есть очень быстрая память, содержащая таблицу (из 32-х регистров по 7 разрядов) соответствия номеров страниц математической памяти номерам страниц физической памяти ОЗУ. Это так называемая таблица приписки. Перед исполнением команды значения 5 старших разрядов исполнительного адреса заменяются значением из таблицы, и получается физический адрес.
Страница с математическим адресом может находиться не в ОЗУ, а в ВЗУ (на магнитном барабане). Тогда эта страница должна быть переписана (подкачена) в ОЗУ и информация о ее нахождении в физической памяти внесена в таблицу приписки. Но ведь это не что иное, как виртуальная память. Таким образом, БЭСМ-6 уже с момента выпуска обладала аппаратом виртуальной памяти.
Если мы обратимся к программе, составленной в гл.2, то замети, что в ней имеется небольшое число рабочих ячеек и ячеек, содержащих переменные и константы, Адреса которых постоянно встречаются в адресной части команд. Это же относится и к командам коротких циклов. Если бы за этими часто встречающимися в программе данными и командами не обращаться каждый раз в оперативную память, а держать их в более быстрой регистровой памяти, то команды выполнялись бы быстрее.
При разработке БЭСМ-6 эта возможность исследовалась и оказалось, что 16 регистров сверхбыстрой памяти существенно ускоряют ход вычислений. Дальнейшее увеличение числа регистров уже влияет слабее. Поэтому были введены 16 полноразрядных (каждый на одно слово) регистров как сверхоперативная память. Отбор чисел и команд в не ведется автоматически из наиболее часто повторяющихся при выполнении программы адресов.
Логически буферная память разбита на три группы:
- буфер командных слов – 4 регистра, дополнены четырьмя 15-разрядными буферами;
- буфер чисел – 4 регистра;
- буфер записи результатов – 8 регистров, дополненных восемью 15-разрядными буферами.
Упрощенная блок-схема взаимодействия устройств БЭСМ-6 изображена на рис. 1. В верхней части изображено ОЗУ, расслоенная на 8 блоков с временным сдвигом к соседнему блоку 0.3 мкс. Команды из ОЗУ попадают в буферный регистр командных слов (БРС) с опережением относительно их исполнения в АУ. При этом сравнивается адрес очередной посылаемой команды с адресами ранее записанных команд, и если адреса совпадают, то посылки команды из ОЗУ не происходит, так как команда уже есть в буфере.
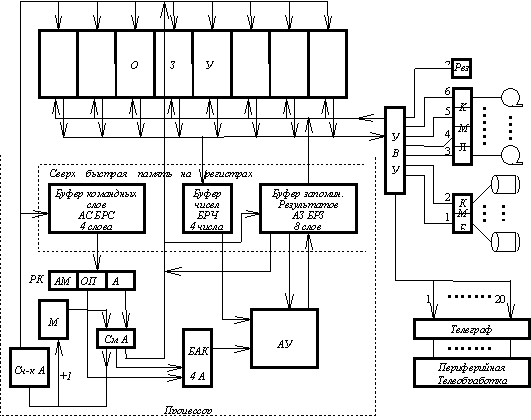
Рис. 1.
Далее идет преобразование адресной части команды в сумматоре (СМА) при помощи сложения ее с содержимым индексного регистра, указанного в команде; так получается исполнительный адрес. После операции приписки он превращается в физический адрес и выбранное по нему слово заносится в буферный регистр чисел (БРЧ). Если операция арифметическая, то выбранное слово – операнд. Тогда КОП этой команды и 3-разрядный адрес операнда в буфере чисел заносятся в блок арифметических команд, находящихся перед АУ. Следовательно АУ получает для выполнения уже заранее подготовленную операцию, подготовка которой производится параллельно с исполнением ранее посланной АУ команды.
Теперь посмотрим, что происходит с результатом после выполнения команды в АУ. Он должен быть переписан в ОЗУ. Но блок, в который должна идти запись, может быть еще не готов к приему. АУ, не дожидаясь готовности блока ОЗУ, переписывает результат с его адресом по ОЗУ в регистр буфера записи результатов (БРЗ) и приступает к выполнению следующей команды. Содержание регистра результата запишется в ОЗУ в порядке очереди записи результатов, но если во вновь поступающих командах встретится этот адрес, т.е. говоря другими словами, результат потребуется как операнд в ближайшей команде, то запись в ОЗУ будет поставлена снова в “хвост очереди”, а результат сможет быть использован как операнд из быстрого регистра записи.
Счетчик команд в УУ функционирует как обычно.
Буфер автоматических команд и связанные с ним быстрые регистры сглаживают разность во времени на выборку команд из ОЗУ и их выполнение в АУ. Во время выполнения коротких операций из него расходуется запас подготовленных команд, а во время выполнения длинных операций (деление, умножение) он вновь полностью заполняется.
Для ускорения вычислений, связанных с автоматизацией программирования, в БЭСМ-6 имеется стековая память, создаваемая на ресурсах ОЗУ. На них также распространяется и ускорение за счет автоматического использования быстрых регистров.
Системное программное обеспечение БЭСМ-6 все время совершенствовалось. Вводились новые операционные системы, режим разделения времени, трансляторы с языков Алгол, Фортран, Лисп и др. С 1970 года в комплектацию машины были включены ВЗУ на магнитных дисках. В эксплуатирующих БЭСМ-6 организациях были созданы комплексы прикладных программ, обеспечивающих проведение важнейших научных и конструкторских расчетов.
Работы в области математического обеспечения БЭСМ-6 сыграли очень важную роль в развитии этого направления науки у нас в стране, в подготовке кадров, в становлении и развитии коллективов разработчиков системного и прикладного программного обеспечения, в развитии сложных многомашинных и сетевых комплексов. Большой вклад внесли коллективы ИТМ ВТ, ИПМ, ОИЯИ, МГУ, ВЦ АН СССР, ВЦ СО АН СССР.
Работа с ВЗУ и периферией. В первоначальном варианте ЮЭСМ-6 в комплект ВЗУ входили накопители на магнитных барабанах (НМБ), а также периферийные устройства перфокарточного ввода-вывода, АЦПУ, перфоленточные устройства ввода-вывода, телеграфные аппараты, а впоследствии дисплеи и графопостроители, модемы телефонной связи и др. МБ было до 16 штук, и каждый из них имел емкость 32К слов.
НМБ и НМЛ обслуживались быстрыми каналами (направлениями). Всего насчитывалось направлений: 2 для НМБ, 4 для НМЛ и седьмое резервное. Каждый канал мог работать одновременно с центральным процессором, обслуживая одно из быстрых устройств внешней памяти. По теперешней терминологии это селекторные каналы. Остальные периферийные устройства обслуживались медленными направлениями.
Для экономии оборудования мультиплексных каналов не было, а медленные направления обслуживались программами ОС, включающимися на время обслуживания по сигналу прерывания. Управление всеми направлениями проводилось блоком управления внешних устройств (УВУ). Таким образом, в БЭСМ-6 была достигнута высокая ступень параллельности (одновременности) работы многих устройств по принципу: все, что в данный момент готово к работе, должно работать!
Эта асинхронность и параллельность в работе устройств наряду с быстродействием АУ обеспечили общую высокую производительность БЭСМ-6. Но для решения некоторых наиболее сложных задач ее оказалось недостаточно и был разработан многомашинный вычислительный комплекс (ММВК).
2. Многомашинный вычислительный комплекс.
ММВК, являющийся развитием ЭВМ БЭСМ-6, представляет собой объединение с помощью параллельных высокоскоростных каналов основных универсальных процессов (в их число входят и ЭВМ БЭСМ-6), отдельных модулей оперативной памяти, специализированных периферийных машин, устройств связи с объектами по приему и передачи информации. “Картина” сети связи указанных устройств заложена в коммутаторах высокоскоростных каналов, что позволяет осуществлять асинхронную передачу между устройствами-абонентами информации, разделенной на слова, т.е. сообщения с указанием в этих сообщениях адресов абонентов получателей.
Включение в комплекс отдельных модулей оперативной памяти, доступной всем процессорам, позволяет иметь большой объем оперативной памяти, гибко распределяемой для задач, решаемых на различных основных процессах (время доступа к этим модулям памяти соизмеримо с временем обращения к обычному ОЗУ процессоров), выполнение программ периферийных машин, обменов данными внешними устройствами, подключенными к этим машинам. Периферийные машины комплекса осуществляют управление выполнением обменов с устройствами ВЗУ и ввода-вывода, освобождая от этих функций основные вычислительные процессы.
Использование периферийных машин, подключенных к общей сети взаимодействующих процессоров и общей оперативной памяти системы, позволяет устройства, подключенные к какой-либо периферийной машине, использовать в задачах, решаемых в разных основных процессорах. С другой стороны, наличие нескольких периферийных машин позволяет объединить подключенные к ним устройства для использования в задачах (или даже в одной задаче), решаемых в одном из основных процессоров системы.
Многомашинность комплексов с фактически обшей оперативной памятью определяется управлением работой каждого основного и периферийного процессора со стороны собственной операционной системы (в комплексе однородных процессоров с общей памятью использование общей для них операционной системы определяет такой комплекс как многопроцессорный).
Взаимодействие операционных систем процессоров (машин) многомашинного комплексано распределению ресурсов комплекса и взаимодействие решаемых задач по передаче информации осуществляется по протоколам транспортного уровня локальной сети ЭВМ, что позволяет рассматривать многомашинной вспомогательный комплекс и как локальную сеть ЭВМ.
“Эльбрус-1-К2” является развитием одномашинных ВС семейства БЭСМ-6. Созданная на базе БЭСМ-6 многомашинная ВС позволила решить целый ряд важнейших задач, но дальнейшему совершенствованию этой системы помешало несколько причин: ориентация на семейства ЕС, а позднее на семейство “Эльбрус”; недооценка стоимости созданного программного обеспечения для БЭСМ-6; недооценка того, что высокопроизводительные комплексы, включая многомашинные и многопроцессорные, потребуются в большом количестве и должны будут заменить БЭСМ-6 в многочисленных ВЦ; наконец, недооценка привязанности программистов к уже освоенной ими архитектуре ВС (включая ОС).
Это привело к тому, что по просьбе организаций-пользователей БЭСМ-6 продолжала выпускаться до 1982 г. В систему был введен интерфейс ЕС, что позволило легко подключить к системе магнитные диски и магнитные ленты от системы ЕС. Ф.В. Тюриным была создана новая операционная система “Диспак”, удачно решавшая вопросы работы в режиме разделения времени, обеспечивающая высокий коэффициент полезного использования системы.
Выпуск в серию ВС “Эльбрус-1” не снял с повестки вопрос о продолжении архитектурной линии БЭСМ-6. Было принято решение один из центральных процессоров ВС “Эльбрус-1” выполнить в архитектуре БЭСМ-6 и сделать его полностью пограммно совместимым с БЭСМ-6.
Наличие ВС “Эльбрус” нескольких ЦП с различной архитектурой, работающих под различными операционными системами, оказалось в большинстве случаев нерентабельным для данной ВС, поэтому была создана ВС “Эльбрус-1-К2”, в которой ЦП, выполненный на новой элементной базе, был полностью совместим с БЭСМ-6, а система управления ВЗУ и периферией была использована от ВС “Эльбрус-1”. При этом несколько сократился объем памяти на МД, так как устройство управления дисками в “Эльбрус-1” было рассчитано на диски меньшего объема, чем УВУ БЭСМ-6, но это сокращение было компенсировано введением быстрых барабанов, усилилась система телеобработки, система воздушного охлаждения была заменена водяным охлаждением, возросла потребляемая мощность системы с 60 до 105 кВт, занимаемая ВС площадь в целом осталась без изменений. Производительность системы возросла в 2,5 – 3 раза.
В то же время стало ясно, что использование в “Эльбрусе-1-К2” устройств управления ВЗУ и периферией от “Эльбруса-1”, рассчитанных на многопроцессорную ВС с развитой сетью телеобработки, не оптимально и работы по созданию более производительных и эффективных ВС семейства БЭСМ-6 следует продолжить параллельно с разработкой новых моделей “Эльбрус”, создавая высокопроизводительную ВС 4-го поколения, с одной стороны, полностью совместимую снизу вверх с БЭСМ-6, а с другой стороны – обладающую новыми архитектурными возможностями, улучшающими характеристики ВС и позволяющими создать на ее базе еще более мощные многомашинные комплексы, как за счет агрегирования нескольких ЦП, так и в сочетании с ВС других серий (“Эльбрус-1”, ЕС и др.). Такой ВС стала “Эльбрус-Б”.
До сих пор в описании БЭСМ-6 отмечались только оригинальность и достоинства ее архитектуры программного обеспечения. Но БЭСМ-6 за 20 лет своего существования претерпела и моральное старение. Это в первую очередь касается характеристик быстродействия, емкости и прямой адресуемости ОЗУ, длины мантиссы (т.е. точности вычислений), надежности (числа часов бессбойной работы), громоздкости конструкции. Последние два параметра во многом зависят от элементарной базы.
При длине адреса 15 разрядов отсутствует возможность прямой адресации ячеек ОЗУ емкостью больше 32К слов, не говоря уже о возможности адресации виртуальной памяти. Переключение управления с одного объекта (32К слов) на другой накладывает ограничение и на производительность, и на удобство программирования.
Точность представления чисел 48-разрядным кодом уже уступает современным ЭВМ большой производительности марки “Эльбрус”, старшим моделям ЕС ЭВМ и затрудняет использование БЭСМ-6 в комплексе с этими ЭВМ.
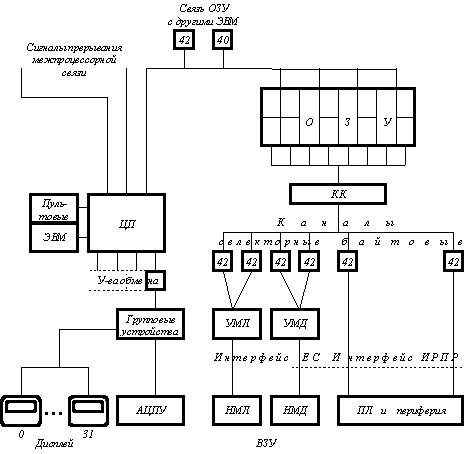
Рис. 2.
Разработанная коллективом под руководством члена-корреспондента Г.Г. Рябова и М.В. Тяпкина ВС “Эльбрус-Б” предназначена:
- для замены ЭВМ БЭСМ-6 “Эльбрус-1-2К” в режиме полной программной совместимости на уровне задач пользователя;
- для решения вновь программируемых задач с использованием расширенных возможностей “Эльбрус-Б”.
- для использования в многомашинном комплексе повышенной производительности из закольцованных ВС “Эльбрус-Б” (до 5 штук);
- для использования в комплексе с супер-ЭВМ различных моделей.
Для обеспечения первых двух задач в “Эльбрус-Б” предусмотрены три режима работы.
- Режим полной совместимости с БЭСМ-6: разрядность чисел 48, разрядность адреса 15, полное повторение системы команд БЭСМ-6.
- Режим работы, повторяющий систему команд БЭСМ-6, но предоставляющий возможность работы с 27-разрядным виртуальным адресом.
- Режим работы с несколько расширенной системой команд БЭСМ-6, с 64- разрядными словами, обеспечивающий точность вычислений и диапазон представляемых чисел на уровне, принятом для высокопроизводительных ВС.
В режиме 3 возможна работа в многомашинных однородных (кольцевых из “Эльбрус-Б”) и неоднородных комплексах. Помимо структуры слов и дополнительных команд это обеспечивается наличием числовых, байтовых и универсальных каналов, легкостью подключения дополнительных устройств ВЗУ и периферии вследствие использования каналов с интерфейсом ЕС ЭВМ.
Состав и взаимосвязь основных устройств “Эльбрус-Б” (см. рис. 2):
- ЦП
- центральный процессор, работающий в одном из трех вышеописанных режимов.
- ОЗУ
- оперативная память комплексов объемом 64 Мбайт с глубиной расслоения 16.
- С0 - С3
- четыре селекторных канала для подключения к процессору внешних устройств (ВЗУ), имеющих интерфейс ЕС ЭВМ.
- Б0 - Б7
- восемь байтовых дуплексных каналов с интерфейсом ИРПР. Эти каналы предназначены для межмашинных связей при создании однородных и неоднородных ММВК.
- КК
- контроллер каналов {Обе группы каналов (С и Б) объединены и подсоединены в режиме прямого доступа к ОЗУ через контроллер каналов (КК). Каналы Б соединяют ВС, удаленные на расстояния десятков метров}.
- У0 – У3
- четыре универсальных канала с программным доступом для устройств с небольшим потоком информации.
- ГУУ
- групповое устройство управления алфавитно-цифровыми дисплеями типа ЕС-2927 и двумя АЦПУ ЕС-7040.
- УМЛ - УМД
- устройства управления восемью НМЛ и НМД соответственно. Подключение устройств управления к двум селекторным каналам сделано из соображений повышения надежности.
- Ч0 - Ч1
- Два числовых канала высокой пропускной способности для обеспечения прямого доступа в оперативную память других вычислительных комплексов
- П0 - П7
- восемь каналов выдачи и приема сигналов прерывания, готовности и конфигурации, предназначенных для организации взаимных межпроцессорных связей в многомашинной системе.
Образование ММВК поддерживается двумя числовыми каналами предназначенными для объединения нескольких ЭВМ “Эльбрус-Б” в единый многомашинный комплекс с топологией кольцо; числовые каналы обеспечивают каждому из ЦП комплекса программный доступ в ОЗУ других процессоров.
Кроме того, возможно объединение ВС “Эльбрус-Б” через ВЗУ. УМД имеют четыре входа. Два из них подключаются к собственным селекторным каналам одной ВС, а два других могут быть подключены к другой “Эльбрус-Б”.
В качестве операционной системы на “Эльбрус-Б” используется разработанная под руководством Ф.В. Тюрина модернизированная ОС “Диспак”. ОС “Диспак” поддерживает как режим короткого, так и режим длинного адреса. Ее возможности и функции значительно развиты по сравнению с ОС “Диспак” БЭСМ-6:
- обеспечено решение до 96 задач пользователей в режиме мультипрограммирования;
- обеспечено решение задач в режимах пакетной, дистанционно-пакетной обработки, в диалоговом режиме, в режиме реального времени как на однопроцессорном, так и на многопроцессорном вычислительных комплексах;
- в диалоговом режиме позволяет использовать до 48-ми терминалов при коротком адресе и до 64-х терминалов при длинном адресе.
ОС “Диспак” эффективно обеспечивает защиту информационных потоков данных в ОЗУ и ВЗУ, самой ОС от несанкционированного доступа и изменения. ОС имеет развитую систему отладочных средств, систему сбора и обработки статистики о работе системы и пользователей на ВС. Значительно расширена по сравнению с БЭСМ-6 система автоматизации программирования. Кроме имевшихся раньше для режима короткого адреса трансляторов с Фортрана, Алгола, Паскаля, автокода система автоматизации программирования “Эльбрус-Б” включает для данного адреса трансляторы с языков: макроассемблер, Фортран ГДР, Модула-2, Алгол-68, С и подготавливаются трансляторы с языков Пролог, Ада и ПЛ/1.
К архитектурным особенностям относятся возможность работы листами памяти переменной длины, которая позволяет оптимизировать подкачку и лучше использовать оперативное запоминающее устройство большого объема.
В табл. 1 приводятся сравнительные характеристики ВС семейства БЭСМ-6.
Таблица 1
|
Характеристики |
БСЭМ-6 |
“Эльбрус-1-к2” |
“Эльбрус-Б” |
| Производительность (млн. оп/с) |
1 |
2.5 – 3 |
4 – 5 |
| Разрядность чисел |
48 |
48 |
48 и 64 |
| Разрядность математического адреса |
15 |
15 |
27 |
| Емкость оперативной памяти (Мбайт) |
0.77 |
0.77 |
64 |
| Емкость памяти на дисках (Мбайт) |
116 |
58+МБ |
800 |
| Площадь маш. зала (м2) |
250 |
250 |
70 |
| Потребляемая мощность (кВт) |
60 |
105 |
25 |
Приведенный пример развития семейства машин показывает конкретную реализацию методов увеличения производительности ВС. Кроме того, следует добавить, что по быстродействию, ВС “Эльбрус-Б” сопоставима с серийно выпускающейся в настоящее время американской ВС CDC Cyber-1808 и обладает высокими показателями надежности.
- Смирнов А.Д. Архитектура вычислительных систем: Учеб. пособие для вузов.- М.: Наука. Гл. ред. Физ.-мат. лит., 1990.-320с
- Процессор ВК Эльбрус 1-КБ. Техническое описание. Ч.1. Принципы построения
Одним из принципиальных моментов разработки МВК “Эльбрус-2” является создание внутренней машинной организации, позволяющей достичь значительного упрощения системы математического обеспечения за счет приближения аппаратных возможностей к нуждам программирования.
Система команд и внутренняя структура МВК “Эльбрус-2”, включающая универсальный стековый механизм, приспособлены для программирования на языках высокого уровня и позволяют осуществлять эффективную компиляцию программ в машинный код. Рекурсивное использование процедур, работа нескольких пользователей с общими данными, практически неограниченный объем математической памяти, предоставляемый в распоряжении пользователя, динамическое распределение и защиты памяти, разветвленная система прерываний существенно облегчают программирование и повышают производительность машины. Высокая производительность МВК “Эльбрус-2” обеспечивается также архитектурными особенностями системы, среди которых прежде всего необходим отметить параллелизм обработки.
Параллельная обработка данных реализуется на двух уровнях — параллельных процессов и параллельного выполнения независимых команд. Первый уровень — это реализация эффективной многопроцессорной системы. второй уровень — обработка команд по принципу поточной линии с максимально возможным совмещением выполнения во времени.
Формально многопроцессорность системы “Эльбрус” заключается в том, что модули центральных процессоров (ЦП) и процессоров ввода-вывода (ПВВ) работают с общей оперативной памятью (ОП) параллельно и независимо друг от друга. Однако такое определение неполно.
Многопроцессорность — это не простое механическое объединение нескольких процессоров с общей памятью. Эффективная мультипроцессорная работа обеспечивается доступом в ОП по восьми независимым каналам, системой взаимного программного прерывания процессоров для синхронизации параллельной работы, аппаратно-реализованными семафорными операциями для синхронизации доступа к общим данным, динамическим распределением ресурсов, прежде всего памяти, повторной входимостью программ, универсальной и совершенной защитой памяти, специальной организацией сверхоперативной буферной памяти и др.
1. Общая организация МВК "Эльбрус-2"
На рис. 1 представлена общая организация МВК.
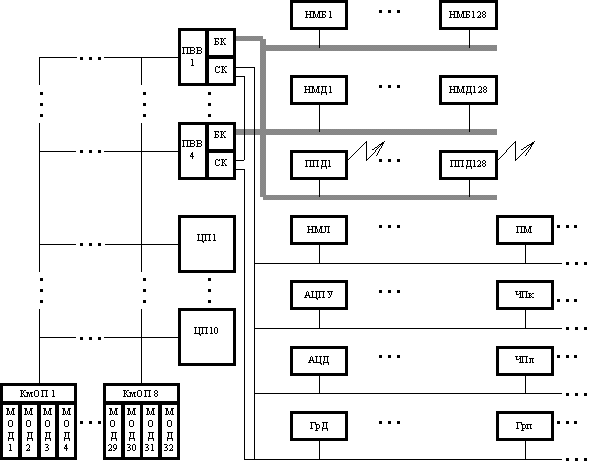
В МВК могут входить от одного до десяти ЦП, от одного до тридцати двух модулей ОП и от одного до четырех ПВВ. Каждый модуль ПВВ имеет 40 каналов связи: 8 быстрых каналов (БК) для магнитных барабанов (НМБ), магнитных дисков (НМД) и 32 стандартных канала (СК) для прочих устройств ввода-вывода. Работа системы с удаленными объектами по линиям связи осуществляется с помощью процессора передачи данных (ППД), который является самостоятельным модулем, имеющим собственную систему команд и внутреннюю память. Каждый из ЦП и ПВВ симметрично связан с каждым из модулей ОП. Через ПВВ к центральной части подключается внешняя память, устройства ввода-вывода и процессоры передачи данных. Обмен данными между оперативной и внешней памятями инициируется ЦП, но происходит независимо от работы ЦП по шинам связи ПВВ.
Все компоненты системы работают параллельно и независимо друг от друга и динамически распределяются операционной системой между задачами. Конкретная конфигурация комплекса зависит от специфики применения. Модульная структура и организация внутренних связей позволяют варьировать состав комплекса и выбирать конфигурацию, соответствующую данному применению. Все модули одного типа полностью идентичны с точки зрения как коммутации, так и энергоснабжения. В случае выхода из строя какого-либо модуля оборудования информация, обрабатываемая в нем, может быть передана в другой модуль. Это значит, что отказ в каком-либо компоненте оборудования не приводит к выходу из строя всего комплекса, а только несколько снижает его производительность. При соответствующем выборе конфигурации модулей комплекс функционирует практически непрерывно. Модульный принцип заложен также в систему охлаждения и систему разводки первичного электропитания.
Максимальная производительность МВК “Эльбрус-2” составляет 120 млн. оп/с, максимальный объем оперативной памяти — 16 млн. 72-разрядных слов (144 Мбайт), максимальная пропускная способность каналов ввода-вывода —120 Мбайт/с.
Центральный процессор МВК “Эльбрус-2” — универсальное вычислительное устройство, предназначенное для решения широкого класса научно-технических и информационно-логических задач. В состав центрального процессора входят устройство управления (УУ), арифметическое устройство (АУ) и сверхоперативное запоминающее устройство (СОЗУ). КмОП — коммутатор оперативной памяти; НМЛ — накопитель на магнитной ленте; АЦПУ — алфавитно-цифровое печатающее устройство; АЦД — алфавитно-цифровой дисплей; ГрД — графический дисплей; ПМ — пишущая машинка; ЧПк — устройство чтения перфокарт; ЧПл — устройство чтения перфолент; Грп – графопостроитель.
Центральный процессор обеспечивает:
- эффективную трансляцию и выполнение программ за счет аппаратной реализации наиболее устоявшихся в языках высокого уровня и операционных системах (ОС) форм описания алгоритмов;
- мультипрограммный режим работы с аппаратной реализацией защиты данных пользователей и ОС и минимальным временем переключения задач;
- высокую производительность, основанную как на применении современной интегральной технологии, так и на параллельной структурной организации и глубоком совмещении выполнения команд;
- эффективную мультипроцессорную работу в вычислительном комплексе, имеющем до десяти ЦП и до четырех ПВВ;
- высокую достоверность вычислений и удобство эксплуатации, основанных на развитой системе аппаратного контроля работы ЦП и аппаратно-программной диагностики.
В ЦП принята безадресная система команд как удобная форма трансляции языков высокого уровня в машинный код. Механизм математической памяти снимает необходимость для пользователя распределять ограниченный ресурс оперативного запоминающего устройства (ОЗУ). Каждой задаче доступна математическая память размером 232 слов, разбитая на страницы по 512 слов. При выполнении задачи в порядке поступления заявок в физической памяти каждой математической странице выделяется сегмент, соответствующий реальному размеру заявки. При переполнении оперативной памяти ОС пересылает часть физических сегментов во внешнюю память (барабаны, диски) и возвращает обратно по мере необходимости. Для ускорения преобразования математического адреса в физический в аппаратуру ЦП введено ассоциативное запоминающее устройство страниц, обеспечивающее быстрый перевод математического адреса в физический.
В ЦП аппаратно поддержана стековая организация памяти. Стек процедур – область математической памяти, в которой динамически размещаются локальные данные (имена и рабочие области) процедур задачи. Области стековой памяти отводятся в порядке обращения к процедурам и освобождаются в обратном порядке по мере их выполнения. В начале каждой области стека размещается связующая информация, хранящая динамическую историю запуска процедур и определяющая адресное окружение текущей процедуры в соответствии с блочной структурой программы. Далее размещается область локальных данных процедуры и рабочая область — область промежуточных результатов. Доступ в разрешенные области локальных данных процедур осуществляется по математическому адресу. Обращение в рабочую область выполняется через вершину стека и только для текущей процедуры.
Для ускорения доступа к локальным данным процедур и увеличения компактности программ используются базовые регистры. Базовые регистры содержат дескрипторы областей локальных данных процедур, открытых для доступа. Адрес по стеку задается в программе номером базового регистра и индексом внутри области локальных данных. С помощью базовых регистров выполняется быстрое вычисление абсолютного адреса.
Для ускорения доступа к промежуточным результатам введено СОЗУ “стек операндов”. Все исполнительные устройства получают операнды и размещают результаты в СтОп. При переполнении СтОп аппаратура обеспечивает автоматическое освобождение части его путем откачки самых “старых” результатов в оперативную часть стека. При опустошении СтОп производится автоматическая подкачка промежуточных результатов из оперативной части стека в сверхоперативную.
Аппаратно реализован механизм процедур, обеспечивающий автоматическое изменение адресного окружения при процедурных переходах, и механизм передачи параметров процедур (по значению, по имени и т.д.).
Адресация оперативной памяти с точностью до бита и специальные операции над наборами битов позволяют эффективно обрабатывать неполноразрядную информацию (например, в алфавитно-цифровом виде). Аппаратно реализованы функции редактирования алфавитно-цифровых массивов (сканирование, пересылка, склеивание фрагментов и т. д.). Аппаратура ЦП позволяет различать наиболее распространенные в языках программирования типы данных (целые и вещественные числа, адреса, наборы битов и т.д.).
Для поддержания мультипрограммной работы в аппаратуру ЦП встроены система точного прерывания, обеспечивающая автоматическое сохранение в стеке состояния прерываемой процедуры, программно устанавливаемые таймеры (на 1 с) и часы. Аппаратно реализована контекстная защита памяти, не позволяющая задаче выйти за пределы отведенных ей областей.
Существенное влияние на производительность ЦП оказывает аппаратная реализация основных операций за счет создания специализированных устройств, ориентированных на выполнение групп алгоритмически близких команд. Кроме того, наличие специализированных функциональных устройств позволяет осуществить одновременное выполнение операций внутри процессора, что приводит к возможности распараллеливания независимых операций.
Используемая в ЦП обработка команд по методу поточной линии позволяет одновременно обрабатывать до 14 команд: две команды — в стадии выборки и дешифрации; 12 команд—в исполнительных устройствах. Параллельно с этим может быть выдано до пяти запросов в память за программным кодом и числовой информацией.
Важный вклад в повышение производительности вносит включение СОЗУ в структуру ЦП. СОЗУ разбито на ряд блоков для хранения данных, имеющих различную динамику старения. Такая организация СОЗУ существенно повышает его эффективность и снижает конфликты одновременного доступа из различных узлов процессора.
Аппаратура процессора обеспечивает упреждающую выборку программы по одному из направлений ветвления и ее выполнение, не дожидаясь вычисления условий передачи управления, отмену и переход на другую ветвь в случае неверного предсказания направления ветвления. Это позволяет сократить перерывы в обработке команд, вызванные ожиданием результата условных передач управления.
Производительность ЦП на смеси Гибсон-З — 12,5 млн. оп/с (8,3 млн. алгоритмических оп/с по ГОСТ 16325—76).
В 1988 г. С. В. Калин измерил производительность ЦП МВК “Эльбрус-2” на 24 ливерморских циклах. Среднее гармоническое значение производительности составило 2,7 М флоп/с. Для сравнения аналогичный показатель у процессора Cray-X МР — 9,3 М флоп/с (при тактовой частоте, в 5 раз превышающей тактовую частоту МВК “Эльбрус-2”).
Система команд ЦП. Центральный процессор МВК “Эльбрус-2” имеет безадресную систему команд, основанную на Польской Инверсной Записи (ПолИЗ).
Прежде чем перейти к описанию системы команд, кратко рассмотрим способ преобразования арифметических выражений исходной программы в последовательность команд считывания, записи и арифметических операций. Обычное трехадресное представление арифметических операций подразумевает наличие в команде адресов операндов и адреса результата. В этом случае выражение
e := a / (b*c - d)
можно представить последовательность команд
R1 : = Сч а
R2 : = Сч b
R3 : = Сч с
R2 : = R2*R3
R3 : = C4 d (1)
R2 : = R2 – R3
R1 : = R1/R2
e: = Зп R1
(где Ri—регистры процессора).
Эти команды делятся на два типа — команды, оперирующие с переменными; программы, и команды, оперирующие с промежуточными результатами.
В 1929 г. польский математик Лукашевич предложил форму записи алгоритмов, отличающуюся от традиционной. В ней появлению операции предшествует появление операндов, каждый из которых может быть результатом предыдущей операции. Так, выражение a+b представляется в виде Сч a, Сч b, +
Воспользовавшись ПолИЗ, приведенную группу команд (1) можно сократить, вычеркнув все ссылки к промежуточным результатом и представив ее в виде Сч а, Сч b, Сч c, *, Сч d, –, /,
ПолИЗ предполагает использование стека в качестве памяти операндов; все операнды считываются из вершины стека, а результаты описываются в вершину стека. При этом явного указания адресов операндов и результата в команде не требуются, поэтому система команд, основанная на ПолИЗ, называется безадресной.
Форматы данных. Центральный процессор может обрабатывать числовые данные следующей длины: 32 разряда (полслова), 64 разряда (слово), 128 разрядов (двойное слово).
Вся управляющая информация имеет словный формат. Кроме того, нечисловая информация может быть представлена в виде битовых, цифровых или байтовых наборов. Каждое слово сопровождается 6-разрядным тегом, определяющим его тип. В памяти значения полусловного формата упакованы в одно слово.
Операции записи в память и считывания из памяти. Адреса для команд записи и считывания задаются операндами адресного типа, которые формируются на основе контекста пользователя. В этих операндах помимо собственно адреса задается возможный формат считываемого или записываемого значения. Для значений полусловного формата адрес по памяти задается с точностью до полуслова, для битовых наборов — с точностью до бита.
Типизация данных позволила реализовать алгоритмы передачи параметров “по ссылке” и “процедурой”. Если результат считывания — адресная информация, то операция считывания автоматически повторяется по новому адресу до тех пор, пока не будет считано значение числового типа; если результат считывания — имя процедуры, то она автоматически запускается и результат ее выполнения рассматривается как считанное значение (рис. 2).
Арифметические и логические операции. Система команд включает в себя базовый набор арифметических операций, работающих с операндами любого числового типа. Так как существует группа принципиально целочисленных алгоритмов, в систему команд введены арифметические операции, контролирующие результат на принадлежность классу целых.
Для обработки битовых наборов предусмотрено два класса команд:
- логические операции (И, ИЛИ, НЕ и т.п.);
- операции выделения и вставления полей.
Работа с массивами предполагает обработку как отдельных элементов массива, так и массива в целом. Для обращения к элементу массива служат операции “Вычислить адрес”, “Вычислить индекс”, “Считать элемент массива”. Специальные операции используются для групповой обработки элементов массива. К ним можно отнести операции пересылки, сканирования, сравнения и редактирования.
Команды передачи управления соответствуют таким конструкциям языков высокого уровня, как безусловный и условный переходы (IF...THEN... ELSE; GO TO; CASE), вызов процедуры, возврат из процедуры и др. Реализация команд процедурных переходов подробно описана ниже.
Команды внутрикомплексного взаимодействия. Для обеспечения эффективного функционирования многопроцессорного комплекса введены операции синхронизации процессов и работы с общими данными.
Безадресная форма системы команд, ее полнота и ориентация на базовые конструкции языков высокого уровня позволили, с одной стороны, обеспечить быструю трансляцию программ, с другой, — получить компактный и эффективный код.
Аппаратная поддержка языков высокого уровня. Для повышения эффективности вычислений в ЦП “Эльбрус-2” аппаратно поддержаны наиболее устоявшиеся конструкции языков высокого уровня. Ниже описаны некоторые, нетипичные для других вычислительных машин, аппаратные механизмы.
Представление данных. Все типы данных можно разбить на несколько классов:
- арифметическо-логический класс, включающий в себя целые словного формата (64 бит), полусловного формата (32 бит), вещественные, а также битовые, цифровые и байтовые наборы;
- класс адресов, объединяющий значения, посредством которых осуществляется адресация к данным (дескриптор, имя) и к объектному коду программы (метки процедур и переходов);
- служебный класс, включающий в себя два типа связующей информации для процедур, а также служебные списки, используемые операционной системой и аппаратурой для работы с данными и кодом в физической памяти;
- класс специальной информации (семафоры) — средства синхронизации при параллельном программировании.
В МВК “Эльбрус” каждая логическая единица информации сопровождается специальным признаком — тегом, который определяет тип и формат. Размер тега — 6 бит.
Аппаратное управление алгоритмами обработки данных. Данные на входе в исполнительное устройство распознаются при помощи тегов и в соответствии с этим производится динамическая настройка алгоритма обработки — либо преобразуются типы, либо в работу включаются разные блоки устройства.
Первым следствием тегирования является уменьшение размера программного кода за счет сокращения номенклатуры операций. Несмотря на то что многообразие типов операндов подразумевает определенную совокупность алгоритмов их обработки, достаточно одной разновидности команды данного типа (одно сложение, одно вычитание и т.п.). Сокращение размера программного кода обусловлено еще и тем, что отпадает необходимость в явном задании преобразования типов и форматов. В машинах с традиционной архитектурой сочетание в арифметических операциях операндов разных типов требует явных операций преобразования типов.
Вторым следствием сопровождения тегами данных и кода является сокращение времени и упрощение процесса трансляции. Транслятору нет необходимости выполнять семантический анализ исходной программы, эту работу выполняет аппаратура.
Повышение уровня динамизма системы. Тегирование данных и кода позволяет использовать такие программы, в которых не требуется статически (т. е. при написании программы) задавать типы обрабатываемых данных. Например, легко реализуются различные способы передачи параметров без указания спецификаций, поскольку наличие тегов и их автоматический анализ позволяют аппаратуре определить, каким способом поданы параметры, и соответствующим образом получить их значения.
Контекстная защита. Концепция тегов позволяет осуществить простую и достаточно надежную защиту данных. Область адресации, или адресный контекст работающей процедуры, определяется совокупностью доступных ей дескрипторов. Вся адресная информация помечена специальными тегами, которые позволяют выполнять только семантически правильные операции.
При этом аппаратура осуществляет контроль за тем, чтобы над адресной информацией не выполнялись действия, которые могут привести к расширению адресного пространства, т. е. к нарушению защиты. Попытка выполнить запрещенную операцию вызывает соответствующее прерывание.
Контекст может меняться только при процедурных переходах и полностью определяется меткой процедуры. Метка процедуры также является адресной информацией и, следовательно, все действия над ней контролируются аппаратурой, что гарантирует сохранность адресного контекста процедуры. Несмотря на то что работающая процедура имеет в своем контексте метки других процедур, вообще говоря, с другими контекстами, доступа к этим контекстам она не имеет, так как единственная возможная операция над меткой — это вызов с ее помощью соответствующей процедуры.
Таким образом, аппаратный контроль обработки адресной информации исключает возможность обращения за пределы того адресного пространства, которое было выделено данной процедуре.
Семантический контроль вычислений. Поскольку для каждой операции определен допустимый набор данных на входе, можно во время выполнения программы контролировать типы входных операндов и сигнализировать соответствующим прерыванием о несоответствии входного типа данных. Вместе с тем предоставляется возможность аппаратного контроля результатов вычислений. Кроме того, теговый механизм позволяет получить наглядное представление структуры данных в памяти в случае диагностической распечатки памяти.
Обработка элементов массивов в цикле. В МВК “Эльбрус-2” предприняты специальные меры для повышения эффективности обработки элементов массивов в циклах.
Массивы занимают смежную область памяти. Начало и размер области, а также формат элементов массива и статус обращения описывает дескриптор массива. Элементы массива расположены таким образом, что приращение индекса по любому из измерений означает “прохождение” по памяти с постоянным шагом.
Аппаратно оптимизирована обработка массивов с количеством измерений, не превышающим трех. Для таких массивов величины шага по памяти в каждом измерении упаковываются в специальное слово, называемое паспортом массива. Дескриптор и паспорт массива, а также индексы по измерениям являются достаточной информацией для обращения к элементу массива.
При использовании массива в цикле каждое из описанных в программе обращений, как правило, предполагает изменение вычисленных индексов от цикла к циклу по линейному закону, т. е. “прохождение” по массиву с постоянным шагом: Это используется для аппаратной оптимизации, реализованной в ЦП.
В устройстве индексации предусмотрена специальная ассоциативная память (АП), в которой запоминается адрес очередного элемента и шаг по памяти. Ассоциативным признаком является имя массива и формула индексирования. В АП может быть помещена информация о шести массивах.
При первом, отличном от других (по формуле индексирования), обращении к массиву по дескриптору, паспорту и начальным значениям индексов вычисляются адрес требуемого элемента и шаг по памяти и заносятся в АП. При последующих обращениях дескриптор и паспорт не требуются, а используется информация из АП. Таким образом, для шести массивов время вычисления адреса элемента в цикле составляет 1 такт.
Кроме того, предусмотрен механизм автоматической предварительной подкачки элементов массивов из оперативной памяти в ассоциативное ЗУ массивов с временем доступа 3 такта. При этом темп подкачки данных, как правило, превышает темп использования.
Описанные механизмы в сочетании с принятой в ЦП поточной организацией позволяют обрабатывать массивы в цикле с высокой эффективностью, несмотря на скалярную форму обращения.
Аппаратная поддержка процедурного механизма. Процедура — фундаментальное понятие языка высокого уровня. Основными атрибутами процедуры являются программный код и контекст, определяющий области доступных данных.
При процедурном переходе необходимо выполнить следующие действия:
- вызов кода;
- определение нового контекста;
- выделение области памяти для локальных данных процедуры при входе (уничтожение области локальных данных при возврате из процедуры);
- передача параметров в новую область локальных данных (передача результатов процедурой-функцией при ее завершении);
- при вызове процедуры — сохранение информации о запустившей процедуре и точке запуска для возврата в нее.
Области памяти (активации) отводятся процедурам в стеке в порядке обращения и освобождаются в обратном порядке по мере их выполнения. Структура активации изображена на рис. 3.
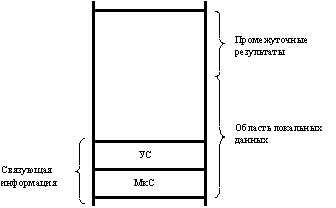
Связующая информация занимает два слова. В первом — маркере стека (МкС) — содержится либо информация об области локальных данных (ОЛД) охватывающей процедуры (для языков с блочной структурой), либо указатель на массив дескрипторов, описывающих COMMON- области (для языков типа ФОРТРАН). Во втором — управляющем слове возврата (УСВ) — сохраняется информация, необходимая для возврата в запустившую процедуру.
–ПРОЦЕДУРА А ( ) % описание процедуры А
·
·
·
D ( ) % вызов процедуры D из процедуры С
·
·
·
–КОНЕЦ % процедуры С
·
·
·
–КОНЕЦ % процедуры D
·
·
C ( ) % вызов процедуры C из процедуры B
·
·
·
–КОНЕЦ % процедуры B
·
·
B ( ) % вызов процедуры B из процедуры A
·
·
·
–КОНЕЦ % процедуры
Структура стека процедур, возникшая в процессе исполнения программы ПРИМЕР (рис. 4), изображена на рис. 5.
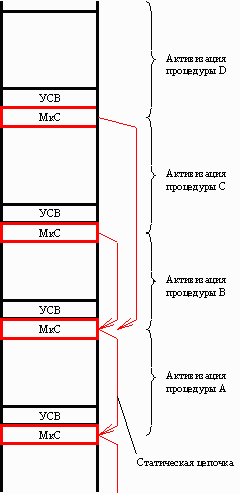
Маркер стека каждой процедуры указывает на начало ОЛД охватывающей процедуры, т. е. на следующий МкС; совокупность маркеров стека, вложенных по программе процедур, образует список (статическую цепочку). На рис. 5 видно, что в соответствии с вложенностью процедур в программе ПРИМЕР, МкС процедуры D указывает на МкС процедуры В, а тот, в свою очередь, на МкС процедуры А. Аналогичная цепочка выстраивается от процедуры С. Совокупность элементов статической цепочки определяет доступные процедуре области данных (контекст, адресное окружение).
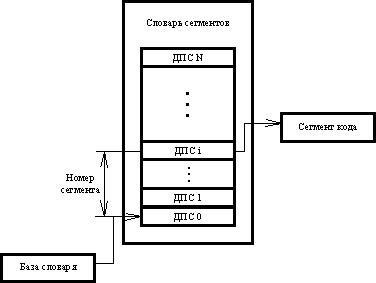
Организация доступа к программному коду. Область памяти, где расположен сегмент кода (программный сегмент), описывается дескриптором; дескрипторы программных сегментов (ДПС0—ДПСN) всех процедур одной задачи упакованы в массив “словарь дескрипторов”, называемый также словарем сегментов; адрес начала массива хранится на специальном регистре “база словаря” (рис. 6).
Каждой процедуре программы соответствует индекс (номер сегмента) по словарю процедур. Таким образом, исходной информацией для вызова программного сегмента являются база словаря и номер сегмента.
Алгоритмы основных вариантов процедурных переходов (вызов процедуры, возврат из процедуры, смена процесса и др.) в ЦП МВК “Эльбрус-2” реализованы аппаратно. Два из них кратко описаны ниже.
Вызов процедуры. Алгоритм вызова процедуры реализуют две команды: “Маркировка стека” и “Вход”. Первая команда предназначена для выделения памяти под локальные данные новой процедуры и сохранения информации об области локальных данных запускающей процедуры. Вторая команда предназначена для завершения формирования информации, необходимой для возврата в запустившую процедуру, осуществления подкачки программного кода, формирования контекста новой процедуры и передачи ей управления.
Исходная информация о вызываемой процедуре задается двумя способами: либо в метке — указателе, описывающем код и контекст процедуры, либо в литеральной части команды. Второй способ является оптимизацией первого для случая, когда имя вызываемой процедуры известно во время трансляции.
По базе словаря, заранее сформированной ОС, и номеру сегмента подкачивается код в соответствии с рис. 6.
При выполнении входа в процедуру установление нового контекста заключается в дублировании соответствующих элементов статической цепочки на специальные базовые регистры ЦП. Первый элемент цепочки задается в метке процедуры. Часто новый контекст отличается от старого только областью локальных данных запускаемой процедуры (в программе ПРИМЕР — вызов процедур В, С). При этом изменение контекста сводится к перезагрузке одного базового регистра и, следовательно, не требует прохождения по всему списку, что существенно снижает время выполнения алгоритма. Наличие такой возможности определяется на этапе трансляции и особо указывается в команде “Вход”.
Область памяти под локальные данные выделяется в стеке процедур командой “Маркировка стека”. Указатель, отмечающий (маркирующий) начало ОЛД текущей процедуры, настраивается на первую свободную ячейку стека, а в управляющем слове возврата формируется ссылка на начало ОЛД запускающей процедуры. После этого возможна передача параметров в ОЛД вызываемой процедуры.
Перед передачей управления в УСВ записывается информация о запускающей процедуре — ее коде, контексте, статусе и т. п.
Возврат из процедуры. На основе связующей информации производится восстановление адресного окружения и обращение за программным кодом “старой” процедуры.
Результаты процедуры-функции передаются в запустившую процедуру через регистры стека операндов. Область локальных данных покидаемой процедуры вычеркивается из стека процедур. Указатель, отмечающий начало ОЛД текущей процедуры, перемещается на начало ОЛД процедуры, в которую происходит возврат.
Аппаратная поддержка обработки нечисловой информации. В ЦП “Эльбрус-2” аппаратно реализован базовый набор операций для эффективной обработки нечисловой информации. Эти операции можно подразделить на несколько групп.
Операции поиска. Типичным методом обработки коммерческой информации является выделение необходимых компонентов из больших массивов на основе заданных признаков. Операции поиска реализуют эту функцию: результатом является указатель на элемент массива, удовлетворяющий заданному условию сравнения с эталоном. Операции этой группы применимы как к массивам, так и к спискам, что облегчает обработку баз данных и других структур, имеющих списковую организацию.
Операции пересылки. Помимо “обычного” перемещения массивов данных в оперативной памяти, в ЦП “Эльбрус-2” возможна так называемая “условная” пересылка. Очередной элемент массива проверяется на выполнение заданного условия сравнения с эталоном (больше, равно и т. п.), при нарушении условия пересылка элементов прекращается.
Операции редактирования. Для работы с текстовыми файлами (создание, модификация и т. п.) выделен особый набор операций, позволяющий выполнять такие функции, как удаление, включение, замена, копирование и другие действия над символами. Это облегчает написание текстовых редакторов и повышает их эффективность.
Функциональный набор операций обработки нечисловой информации включает в себя также аппаратно реализованные алгоритмы упаковки, распаковки, сканирования, сравнения массивов и др.
Структура ЦП. На рис. 7 представлена структурная схема ЦП, в состав которого входят:
- устройство обмена с оперативной памятью (УООП);
- буферная память команд (БК) для согласования темпа дешифрации команд и вызова программы из оперативной памяти;
- устройство управления (УУ);
- 10 специализированных исполнительных устройств (ИУ) для выполнения команд;
- устройство базовых регистров (БР) для преобразования относительных адресов в абсолютные;
- стек операндов (СтОп) для хранения промежуточных результатов операций;
- буферная память (БП).
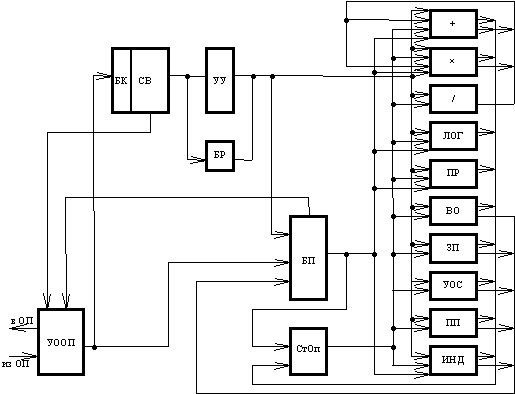
СВ – схема выборки; СтОп – стек операндов
Конструктивно ЦП состоит из трех функционально законченных шкафов, каждый из них содержит шесть панелей, с помощью которых производится коммутация 240 ячеек.
В ЦП используется глубокое совмещение выполнения команд по методу последовательно-параллельной поточной линии.
Последовательная часть поточной линии включает в себя вызов командных слов, распаковку и дешифрацию команд, преобразование команд из внешнего безадресного представления во внутренний регистровый формат. Оставшаяся часть поточной линии представляется параллельными ветвями, ориентированными на выполнение групп алгоритмически близких команд. Каждая ветвь реализована в виде автономного блока — исполнительного устройства с развитым внутренним управлением.
Сверхоперативное запоминающее устройство состоит из нескольких специализированных ЗУ:
- буфера команд;
- стека операндов;
- буферной памяти для сокращения времени обращения к часто используемым адресуемым переменным в стеке;
- базовых регистров;
- ассоциативного запоминающего устройства страниц, для быстрого преобразования математических адресов в физические.
Блоки ЦП. Здесь описываются функциональное назначение и некоторые характеристики наиболее существенных блоков центрального процессора, что позволяет получить более детальное представление о структуре машины.
Командный блок обеспечивает непрерывность потока команд на дешифрацию, для чего осуществляет вызов командных слов из оперативной памяти, создает необходимый запас этих слов, а также выполняет их распаковку. Сверхоперативная буферная память команд позволяет хранить большой объем ранее вызванной информации на случай ее повторного использования. Управление командным блоком обеспечивает выполнение команд передачи управления и организацию циклических программ, при этом перерывы в дешифрации команд, связанные с переходом, организующим цикл, отсутствуют.
Основу командного блока составляет ассоциативная буферная память команд (БК) секторного типа объемом 512 слов. БК позволяет организовать хранение 32 командных сегментов. Сектор буферной памяти в 16 слов выделяется перед его непосредственным использованием, а расположение в БК не зависит от места командного сегмента в ОЗУ. Подкачка информации в БК из оперативной памяти производится блоками по четыре слова.
Командные слова считываются на две пары регистров дешифрируемых команд (РДК). Одна пара РДК служит для создания запаса команд на линейном участке программы, а другая — в направлении предполагаемого ветвления. Объем РДК и скорость считывания из ВПК обеспечивают максимальный темп дешифрации в две команды за такт.
Ветвления внутрь ВПК и повторное использование ранее вызванных процедур происходят без обращения в УООП, что является мощным фактором увеличения реального быстродействия ЦП.
Устройство управления выполняет следующие функции:
- преобразует команду из внешнего безадресного представления во внутренний регистровый формат. Полем операндов является сверхоперативное запоминающее устройство—стек операндов;
- управляет распределением ячеек памяти стека операндов в потоке параллельно выполняемых команд;
- распределяет команды по исполнительным устройствам;
- считывает операнды в исполнительные устройства из стека операндов;
- выполняет первичные обращения в буферную память для команд, в коде которых содержатся адреса;
- обеспечивает хранение информации о последовательности дешифрации параллельно выполняемых в ЦП команд;
- обеспечивает восстановление состояния ЦП при прерываниях и отменах условной ветви выполнения программы.
Темп обработки команд в устройстве управления может колебаться от двух команд за 1 такт до одной команды за 3 такта. С максимальным темпом обрабатываются наиболее распространенные сочетания команд:
“считать величину” и арифметическая команда;
“загрузить адрес” и “взять элемент массива”;
“загрузить адрес” и “записать”.
Устройство базовых регистров предназначено для преобразования относительных адресов из командного потока в абсолютные (математические или физические). Устройство содержит 32 базовых регистра, каждый из которых описывает определенную область памяти, т. е. содержит начальный адрес области, ее размер и некоторую информацию, определяющую способ обращения в эту область. Занесение дескрипторов в БР выполняет ИУ подпрограмм при командах процедурных переходов.
Относительный адрес в команде представляется в виде адресной пары — номера базового регистра и индекса (смещение относительно начального адреса области). Преобразование осуществляется суммированием начального адреса с индексом. Одновременно проверяется, не превышает ли индекс размера заданной базовым регистром области памяти.
Результатом преобразования является указатель на начинающуюся с вычисленного адреса часть области памяти, описанной в базовом регистре.
Стек операндов является сверхоперативным запоминающим устройством, предназначенным для ускорения доступа к данным, размещаемым в вершине стека. Стековую дисциплину назначения, использования и освобождения ячеек операндов поддерживает устройство управления.
По методу доступа стек операндов — обычная прямо-адресуемая память на 32 двойных слова. Доступ в стек операндов выполняется от восьми абонентов на основе приоритетной схемы. Устройство управления обращается в стек операндов по записи при выполнении команд литеральной загрузки и по считыванию при выдаче команд в исполнительные устройства, остальные абоненты (исполнительные устройства и буферная память) — только по записи. Запись и считывание информации занимают 1 такт.
Буферная память данных — сверхоперативное полупроводниковое запоминающее устройство объемом 1536 слов по 70 разрядов. Быстродействие БП соответствует быстродействию процессора. Запросы в устройство БП могут поступать с тактовой частотой процессора. В буферной памяти хранится новая активно используемая информация. При отсутствии в буферной памяти запрашиваемых данных организуется заявка в оперативную память. Из оперативной памяти считывается и помещается в БП блок из четырех слов, в котором содержится необходимая информация. В устройстве БП также остается ассоциативный признак—математический адрес блока.
Буферная память данных включает устройства трех видов: ЗУ стекового типа — буфер стека объемом 256 слов; ассоциативное ЗУ (АЗУ) глобальных данных объемом 1024 слова и АЗУ массивов объемом 256 слов. Каждое из устройств ориентировано на работу с данными определенного типа, имеющими свою динамику использования и соответственно старения.
Буфер стека (БС) предназначен для хранения активаций последних (в порядке запуска) процедур. Целесообразность выделения для этого специального блока БП обусловлена тем, что область данных, создаваемая каждой процедурой, является локальным объектом, время жизни которого не превышает времени выполнения соответствующей процедуры. Информация, заносимая в БС, не копируется в ОП, специальный указатель отмечает границу между областями стека процедур, расположенными в БС и ОП. Аппаратно БС реализован по принципу “барабана”, при переполнении ВС часть данных переписывается в ОП, а указатель границы сдвигается.
АЗУ глобалов (АЗУГ) предназначено для хранения и быстрого доступа к часто используемым глобальным переменным, не попавшим в границы ВС. Схема старения обеспечивает сохранение в АЗУГ наиболее часто используемой информации и замещение самой “старой”.
АЗУ массивов (АЗУМ) ориентировано на работу с данными, организованными в виде массивов, последовательность поступления которых, как правило, известна заранее, а использование в большинстве случаев однократно. Занесение в АЗУМ данных из ОП выполняется параллельно с поиском и считыванием хранящейся информации, что позволяет организовать подкачку элементов массивов впрок.
В качестве ассоциативного признака в АЗУГ и АЗУМ используется математический адрес требуемой информации.
В устройстве БП предусмотрено параллельное выполнение ряда операций. При обращении в ОП и поступлении данных из нее прием новых заявок и их выполнение не прекращаются. БП обрабатывает заявки по конвейерному принципу. Длина конвейера — 3 ступени, темп обработки —1 заявка за такт.
Соответствие математической и физической страниц памяти определяется таблицей страниц, организованной в виде списка. Для ускорения преобразования математического адреса в физический в ЦП предусмотрено АЗУ страниц (АЗУС), в котором сохраняются элементы таблицы для наиболее “активных” страниц. Объем АЗУС— 64 строки. Ассоциативным признаком является номер математической страницы, закодированный в математическом адресе заявки. В ответной части расположены физический адрес начала страницы, ее размер, а также некоторые служебные признаки. Темп обработки в ДЗУС—1 заявка за такт, время преобразования (при наличии элемента таблицы страниц в АЗУС) —3 такта. Отсутствие требуемой страницы в АЗУС приводит к автоматическому поиску по таблице страниц и занесению соответствующего, элемента в АЗУС.
Исполнительное устройство сложения предназначено для выполнения операций сложения, отношения и преобразования типов и форматов над целыми и вещественными числами. Время выполнения операций над целыми числами составляет 2—3 такта, над вещественными — 3—5 тактов. Устройство обеспечивает автоматическое изменение алгоритмов выполнения операций при использовании разноформатных и разнотипных операндов.
Выполнение операций над вещественными числами формата Ф128 требует трехкратного сложения—сложения младших разрядов, сложения старших разрядов с учетом переноса из младших разрядов, повторного сложения младших разрядов с учетом переноса из старших разрядов. Устройство обрабатывает команды по методу поточной линии с четырьмя станциями хранения. Назначение входной станции — прием команды и ее хранение до тех пор, пока не будет получен комплект операндов, необходимых для выполнения операции. Входная станция сдвоена, т. е. может хранить две команды. Операнды могут поступать из СтОп, буферной памяти, устройства умножения и с выхода самого ИУ сложения. Команда, первой набравшая комплект операндов, выдает заявку в схему управления для обеспечения дальнейшего продвижения команды.
Исполнительное устройство умножения выполняет операции арифметического умножения, умножения с двойной точностью и целочисленного умножения. Первые две операции выполняются над целыми и вещественными числами, третья—только над целыми.
В основу алгоритма умножения положена быстрая схема умножения, использующая пирамиду сумматоров и позволяющая за одну итерацию произвести умножение на 28 разрядов множителя. Время выполнения одной итерации равно 2 тактам. Время умножения целых чисел до 28 разрядов равно 3 тактам; больше 28 разрядов, но меньше 56 разрядов,— 5 тактам; больше 56 разрядов—7 тактам. Умножение вещественных чисел формата Ф32 составляет 3 такта, формата Ф64—5 тактов.
ИУ умножения может получать операнды из стека, буферной памяти, ИУ сложения и с выхода самого ИУ умножения. Входная станция, первой набравшая комплект операндов, выдает заявку в схему управления, обеспечивающую выполнение операции в устройстве.
Исполнительное устройство деления предназначено для выполнения операций арифметического деления, целочисленного деления и остатка от деления целых и вещественных чисел. Арифметическое деление выполняется над вещественными и целыми числами любого формата, результат операции—вещественный. Операнды и результат целочисленного деления принадлежат классу целых.
Исполнительное устройство деления выполняет деление по методу без восстановления остатка с определением за одну итерацию трех цифр частного. Арифметическое деление вещественных чисел формата Ф32 занимает 12 тактов, вещественных чисел формата Ф64— 23 такта.
Целочисленное деление в зависимости от числа значащих цифр частного занимает 6—24 такта.
Входная станция предназначена для хранения одной команды и накопления ее операндов. На входную станцию операнды принимаются из стека операндов.
Исполнительное устройство логической обработки (ЛОГ) предназначено для выполнения логических операций, операций над наборами и операций преобразования типов.
Основное содержание операций над наборами — выделение или вставление поля произвольной длины (в пределах слова).
В операциях преобразования типов производится замена тега исходного операнда в соответствии с кодом операции без изменения информационных разрядов.
Устройство обрабатывает команды по методу поточной линии с двумя станциями хранения — входной и выходной. Устройство получает данные из стека и буферной памяти, а также с выхода ИУ логической обработки и из устройства управления. На выходную станцию результат поступает спустя 2 такта для всех операций устройства.
Исполнительное устройство десятичных преобразований (ПР) выполняет две операции — преобразование числа из десятичного представления в битовый набор и преобразование из битового набора в десятичное представление. Обе операции выполняются в устройстве за 34 такта.
ИУ десятичных преобразований получает операнд из стека; оно не имеет собственного выхода в стек и использует шину ИУ деления.
Исполнительное устройство вызова и записи операндов (УВЗ) объединяет два автономных устройства: устройство вызова операндов в стек (ВО) и записи операндов в оперативную память (ЗП), каждое из которых выполняет свой набор команд. Кроме того, УВЗ принимает участие в выполнении еще ряда команд совместно с исполнительными устройствами индексации (УИНД) и обработки строк (УОС).
Устройство вызова операндов выполняет операции загрузки в стек информации, адрес которой принимается из устройства управления (при этом первичное обращение в память осуществляет устройство управления, а устройство ВО делает вторичные запросы, если вызванная величина оказалась адресным словом или старшей половиной слова удвоенной точности) или из стека.
Устройство записи выполняет операции записи с преобразованием записываемой информации в соответствии с кодом операции, типом и форматом записываемой величины.
Устройство ВЗ принимает также исходные операнды для команд устройства ИНД; кроме того, совместно с ИНД УВЗ выполняет операции, связанные с адресацией к элементам массивов.
Прием операндов и команд в УВЗ выполняется на буферные регистры из устройств УУ, ИНД, БП и стека.
Исполнительное устройство обработки строк (УОС) предназначено для выполнения операций над символьной (алфавитно-цифровой), цифровой и битовой информацией, перемещения массивов в памяти, поиска информации по заданным признакам, сравнения массивов.
Устройство выполняет операции:
- пересылки и рассылки элементов массивов безусловно;
- пересылки элементов массивов с проверкой заданного отношения;
- пересылки элементов с преобразованием и редактированием;
- сканирования массивов на сравнение с заданными признаками;
- упаковки и распаковки алфавитно-цифровой информации.
Основное содержание операций — поэлементное перемещение массива источника в массив стока (назначения) с анализом перемещаемой информации, пропуском или добавлением части элементов из командного потока или специальной таблицы редактирования. Операции выполняются методом поэлементной упаковки в очередном слове массива стока элементов из очередного слова массива источника.
Во всех операциях обработки массивов схема анализа размеров дескрипторов определяет выход за границы массивов.
Устройство обработки строк не имеет самостоятельных шин связи с управлением, стеком и памятью и использует УВЗ как буфер. Так, команду и исходные данные УОС получает через входную станцию устройства записи и использует весь комплект входных числовых регистров УВЗ при выполнении операций.
Устройство обработки строк использует выходную шину УВЗ для обращения в память (вызов и запись слов массивов) и для записи результатов операций в стек операндов.
Исполнительное устройство подпрограмм (ПП) участвует в выполнении операций, связанных со входом в процедуры и возвратом, а также команд перехода. Устройство выполняет команды считывания и записи в системе прямоадресуемых регистров процессора, операции откачки и подкачки при регулировании состояния стека операндов, операции взаимодействия процессоров.
Основное содержание операций процедурных переходов состоит в формировании управляющих слов (меток, маркера стека и управляющего слова возврата), записи и считывании слов из оперативной памяти, коррекции содержимого базовых регистров в соответствии со связующей информацией стека процедур, описывающей текущую процедурную вложенность, загрузке регистров счетчика команд в командном блоке.
Алгоритмы большинства операций устройства подпрограмм заключаются в формировании или модификации отдельных полей управляющих слов. Управляющие слова формируются заново или поступают из оперативной памяти, а затем отсылаются в СтОп, оперативную память или базовые регистры.
Большинство прямоадресуемых регистров ЦП размещено в устройстве подпрограмм. В их число входят регистры, описывающие состояние стека процедур (указатели вершины, дна, верхней границы, маркера стека текущей процедуры), регистры баз некоторых таблиц ОС, таймер, часы, регистры конфигурации памяти и процессоров, регистры прерываний. Операции с регистрами заключаются в обмене информацией между вершиной стека и прямоадресуемыми регистрами.
Исполнительное устройство индексации выполняет операции индексации, преобразования адресных слов, аппаратной организации программных циклов, вычисления индекса и адреса элементов массивов с размерностью не более трех. Основное содержание операций индексации — это вычисление адреса элемента массива по заданным дескриптору массива и индексу элемента в массиве. Одновременно с вычислением адреса производится проверка того, не превышает ли индекс размера массива, описываемого дескриптором. Время выполнения операций индексации — 1,5 такта.
При совместной работе с буфером команд по организации программных циклов устройство принимает начальные и предельные значения переменных цикла, осуществляет приращение (±1) текущих значений переменных цикла и их сравнение с предельными, вырабатывая сигнал условия конца цикла, Кроме того, устройство позволяет считывать в вершину стека значения текущих переменных цикла. Время выполнения операций в устройстве от 1 до 2,5 тактов.
Взаимодействие устройств ЦП. Командный блок обеспечивает подкачку программы в буферную память команд (БК). Темп подкачки определяется необходимым запасом командных слов в буфере команд и автоматически регулируется при изменении темпа дешифрации команд. Схема выборки извлекает очередную команду из БК, дешифрирует и передает в УУ для преобразования во внутренний регистровый формат. Устройство управления, сформировав исполнительное представление команды, выдает ее в соответствующее исполнительное устройство и считывает необходимые операнды из стека. Одновременно устройство базовых регистров преобразует относительные адреса из командного потока в абсолютные адреса на фоне формирования исполнительного вида команды в УУ.При выдаче команды УУ использует адрес, полученный в БР, и выдает его в соответствующее ИУ для дальнейшего использования.
Исполнительное устройство, получив команду и комплект операндов, выполняет заданную команду и помещает результат по назначенному адресу в стек операндов или обращается в БП. Если при обращении в память по считыванию обнаруживается, что ячейка с заданным адресом имеется в буферной памяти, то выборка числа производится из БП, а обращение в оперативную память отменяется. В противном случае делается обращение в оперативную память, вызванное число поступает в назначенный регистр стека операндов и заносится вместе с адресом в БП для возможного повторного использования. Запись информации выполняется параллельно в БП и оперативную память.
Система внутренней адресации. Все передачи адресной и числовой информации сопровождаются в ЦП внутренним адресом источника или потребителя информации. Внутренние адреса присвоены буферу команд, стеку операндов, БП и некоторым входным регистрам ИУ.
При выдаче команды в ИУ устройство управления формирует внутренние адреса операндов и результата операции. ИУ, получив команду и комплект внутренних адресов, дожидается появления на числовых шинах данных с соответствующими внутренними адресами. Если операнд, который, как правило, является результатом одной из предшествующих операций, “готов” к моменту его использования, то УУ считывает его из стека операндов. Иначе ИУ обнаружит операнд на числовых шинах в момент его записи в стек.
Используемый метод позволяет УУ раздавать команды в ИУ, не дожидаясь готовности операндов. Следствием этого является высокая степень параллелизма в работе исполнительных устройств.
Шины прямой связи. Все команды получают операнды из СтОп и помещают результат в вершину стека. Вершина стека в ЦП представлена СОЗУ стека операндов, который является транзитным буфером при передаче результатов команд в качестве операндов в последующие. В большинстве случаев ИУ получают команды раньше, чем будут сформированы операнды.
Для ускорения доставки операндов введены шины прямой связи. Шина БП—ИУ ускоряет доставку результатов команд считывания из памяти, используемых в ИУ в качестве операндов. Исполнительные устройства сложения и умножения охвачены прямой шиной передачи результатов непосредственно на собственные входы.
Параллельная обработка. Корректность и эффективность вычислений. Параллельная обработка является одним из основных способов повышения производительности вычислительных средств. Однако реализация параллельной работы исполнительных устройств ЦП связана с определенными трудностями. Во-первых, необходимо обеспечить эффективное динамическое распределение некоторых общих ресурсов процессора. Во-вторых, параллельная работа ИУ затрудняет идентификацию точки останова вычислительного процесса и возможность его корректного продолжения.
Динамическое распределение регистров. При организации стековой памяти верхние ячейки стека размещаются в сверхоперативной памяти процессора. Эта часть стека занимает 32 слова удвоенной длины и реализована на триггерных схемах. Остальная часть стека размещается в буфере стека и оперативной памяти.
Использование сверхоперативной памяти в качестве верхних ячеек стека обеспечивает быстрый доступ к промежуточным результатам и основывается на методе динамического распределения регистров. Суть его в следующем. Вся сверхоперативная память — 32 регистра удвоенной длины — рассматривается как ресурс свободных ячеек, которые назначаются под результат очередной команды и освобождаются после использования в качестве операндов в последующих командах. Ресурс свободных ячеек представляется в виде 32-разрядного регистра (вектор свободных регистров), в котором каждой ячейке сверхоперативной памяти соответствует своя позиция, при этом номер позиции является адресом ячейки. Признаком занятости ячейки является код 1 в соответствующей позиции. Поиск свободной ячейки состоит в поиске разряда, содержащего код 0. В случае дешифрации двух команд за один такт одновременно может производиться выборка двух свободных ячеек. После освобождения ячеек в результате выполнения очередной операции производится установка в 0 соответствующих позиций.
Такая организация СтОп обусловлена тем, что объединение собственно числовых регистров по стековому принципу имеет ряд недостатков. Наиболее существенный — возможность обращения в стек только через его вершину, что предопределяет принципиально последовательный алгоритм исполнения программ. Это не позволяет эффективно использовать парк ИУ.
Описанный здесь механизм, при котором стековой дисциплине подчинены не регистры операндов, а их номера в СОЗУ, и соответственно УУ манипулирует не операндами, а их номерами, позволяет, во-первых, не дожидаться готовности результата предшествующей операции для запуска последующей, во-вторых, оптимальным образом аппаратно распределять ресурс сверхоперативной памяти при трансляции внешней безадресной системы команд во внутренний регистровый формат. Процесс дешифрации не зависит от реального выполнения команд в ИУ и может значительно опережать его.
При переполнении сверхоперативной части стека происходит автоматическая откачка информации в буфер стека, при его опустошении — автоматическая подкачка.
Управление очередью команд. Наличие специализированных ИУ, работающих параллельно, позволяет одновременно обрабатывать в процессоре несколько команд. Устройство управления последовательно раздает команды в специализированные ИУ; ИУ, выполнив операцию, самостоятельно записывает результат в заданную ячейку СтОп. Время выполнения команд в ИУ определяется их типом и колеблется от 2 до 20 тактов для операций над операндами однократной точности и до 30 тактов над операндами удвоенной точности. Таким образом, временная последовательность выполнения команд может не совпадать с последовательностью дешифрации.
В некоторых случаях бывает необходимо восстановить заданную программой последовательность команд. Например, при возникновении прерывания важно идентифицировать вызвавшую его команду, обеспечить выполнение всех предыдущих и отмену всех последующих по порядку дешифрации команд; при условных ветвлениях неверный выбор направления опережающего исполнения приводит к отмене “ненужных” команд; исполнение операций, изменяющих состояние вычислительного процесса (записи в память, передачи управления и т.п.), требует безаварийного завершения всех предшествовавших команд. Возникает задача обеспечения корректности вычислений при одновременной параллельной работе ИУ.
Решению этой задачи служит специальный узел - очередь выполнения команд. Из УУ команды выдаются в последовательности, заданной программой. При дешифрации они последовательно нумеруются. Номер команды (NK) сопровождает команду по всем станциям поточной линии обработки от дешифрации до окончания. Этот номер является адресом по специальной памяти, в которой сохраняется информация о состоянии основных регистров УУ, достаточная для повторения вычислений. УУ располагает ресурсом в 32 номера (от 0 до 31), после чего номера повторяются. Таким образом, одновременно на стадии исполнения может находиться не более 32 команд. Это позволяет в упомянутых ситуациях восстанавливать естественную последовательность команд перед особой точкой вычислительного процесса (момент прерывания, записи и т.п.) и при необходимости продолжать с нее вычисления.
Обработка прерываний. Режим условного выполнения. Контроль корректности вычислительного процесса, организация мультипрограммной и мультипроцессорной работы МВК, ликвидация последствий случайных сбоев аппаратуры реализованы через механизм прерываний.
В случае возникновения прерывания УУ выполняет следующие действия:
- запоминает индекс команды, вызвавшей прерывание;
- обеспечивает выполнение команд, дешифрированных ранее, и отменяет выполнение команд, дешифрированных позднее команды, вызвавшей прерывание;
- восстанавливает состояние регистров УУ на момент, соответствующий дешифрации команды, вызвавшей прерывание;
- инициирует аппаратный вход в процедуру обработки прерывания (вход выполняется в ИУ подпрограмм).
Отмена выполнения команд используется также при обработке команд условного перехода. Тот факт, что очередной команде под результат всегда назначается свободный в данный момент регистр, а ячейки операндов освобождаются только при исключении выполненной команды из очереди, позволяет выполнять команды, следующие за командой условного перехода, не ожидая его результата. При этом все команды дешифрированные за командой условного перехода, помечаются признаком условного выполнения. Если условие перехода не выполняется, то выполнение продолжается, как будто команды перехода не было, а признак условного выполнения гасится на всех станциях ЦП. Если условие перехода выполняется, то команды, помеченные признаком условного выполнения, отменяются, восстанавливается состояние регистров УУ на момент команды перехода и управление передается альтернативной ветви.
3. Организация оперативной памяти
Подсистема оперативной памяти является важным компонентом структуры многопроцессорной вычислительной системы и оказывает значительное влияние на ее характеристики. Связь центральных процессоров и процессоров ввода-вывода с памятью и между собой, взаимодействие процессоров при параллельной работе, возможные конфликты из-за общих ресурсов системы определяют типы вычислительных систем (сильно- и слабосвязанные, эгалитарные и автократические и т.п.), существенно влияют на производительность, надежность и гибкость МВК. Коммутационное оборудование может составить значительную часть аппаратуры комплекса [15].
Краткий обзор систем коммутации — от схем с общей шиной до многоуровневых коммутационных сетей — с примерами их применения в конкретных ЭВМ приведен в работе Е. Валяха [14].
В МВК “Эльбрус” для связи процессоров с оперативной памятью применена многопортовая-многошинная схема коммутации с топологией соединений по полному графу (каждый с каждым). Такая схема (см. рис. 1) позволяет получить максимальную скорость передачи информации и одновременно обеспечивает высокую надежность и гибкость системы, так как наилучшим образом соответствует принципу модульности.
Недостатками данной схемы являются большое число линий связи и значительный объем коммутационного оборудования, а также то, что максимальная конфигурация системы ограничена числом портов, имеющихся в коммутаторах процессоров и секций памяти.
В связи с этим применение многопортовой-многошинной полноперекрестной схемы коммутации оправдано для высокопроизводительных МВК, состоящих из небольшого числа мощных процессоров и секций памяти большой емкости, каким и является МВК “Эльбрус”.
Оперативная память МВК “Эльбрус” имеет блочную структуру. Минимальный размер блока — 16 К слов — соответствует объему микросхемы памяти 16 К бит. Блок состоит из 80 микросхем памяти, по одной микросхеме на разряд (слово, хранящееся в памяти, содержит 80 разрядов, включая контрольные разряды кода Хемминга).
Для сокращения числа линий связи, коммутационного и управляющего оборудования блоки объединяются по иерархической схеме. На рис. 8 представлена блочная структура оперативной памяти для одного разряда. Секции ОП (0—7) размещены в отдельных шкафах и имеют линии связи со всеми процессорами. Модули памяти (0—31) имеют собственное коммутационное и управляющее оборудование. Группы микросхем имеют собственные шины управления и регистровое обрамление.
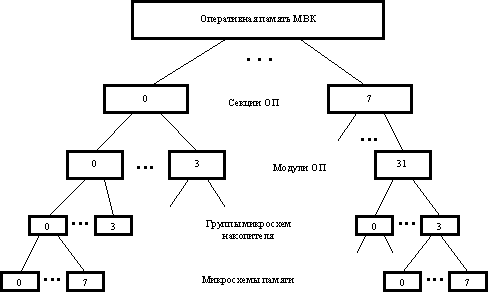
Для повышения пропускной способности памяти применяется распределение последовательных адресов по разным блокам памяти (интерливинг). В МВК “Эльбрус” возможен интерливинг разных уровней: между секциями памяти; между модулями секции; внутри модуля секции памяти.
Коммутационное оборудование распределено между процессорами и секциями оперативной памяти и является составной частью ЦП и ОП соответственно. Длина линий связи выбрана примерно равной 10 м из условия размещения устройств комплекса.
При такой длине связей сигналы передаются от выходного регистра передающей станции до регистра приемника за два такта (80 нс). По информационной части шин требуется обеспечить передачу сигналов с темпом в одно слово за такт. Для обеспечения надежной передачи применяются парафазные линии связи. В то же время для экономии кабелей в информационных шинах применена двусторонняя передача сигналов. Таким образом, информационные шины выполнены по двусторонней парафазной схеме. По каждой линии, кроме информации, передается 24-разрядное управляющее слово (адрес и код операции) и около 10 служебных сигналов.
Максимальный объем оперативной памяти МВК “Эльбрус-2” составляет 16 млн.слов (144 Мбайт). Максимальный темп обмена с каждым процессором составляет ~180 Мбайт/с.
Секция оперативной памяти. В максимальной конфигурации МВК “Эльбрус” содержит десять центральных процессоров, четыре процессора ввода-вывода и восемь секций оперативной памяти (см. рис. 1).
Секциями памяти МВК “Эльбрус-2” являются устройства ЭПП (электронная полупроводниковая память). Устройство ЭПП состоит из четырех модулей памяти и коммутатора (КмОП). Модули функционально независимы и могут одновременно обмениваться информацией с разными процессорами.
В качестве запоминающих элементов в накопителе используются БИС ЗУ565РУЗВ емкостью 16 К бит. Модуль памяти содержит 512 К 72-разрядных слов. Емкость секции ЭПП — 2 М слов (18 М байт).
В модулях памяти реализована групповая обработка, позволяющая за один цикл обращения записать или считать четыре слова. Для этого модуль разбит на четыре группы микросхем (см. рис. 8), обращения к которым чередуются при последовательном переборе адресов.
При групповом обращении все четыре группы запускаются одновременно. Это позволяет получить максимальный темп обмена с секцией памяти 450 Мбайт/с. Для повышения темпа обмена и уменьшения среднего времени доступа в ЭПП используется также совмещение операций. Цикл работы модуля составляет 13 тактов, однако последовательные обращения к разным микросхемам одной группы могут обслуживаться каждые семь тактов.
Аппаратура коррекции и контроля позволяет исправлять одиночные и обнаруживать двойные ошибки при считывании информации. Для этого при записи формируются и добавляются к 72-разрядному информационному слову восемь разрядов кода Хемминга.
Коммутатор оперативной памяти. Коммутатор оперативной памяти (рис. 9) обеспечивает связь четырех модулей секции ОП с четырнадцатью процессорами МВК. Основными частями КмОП являются схема приоритета, блок временных диаграмм (ВРД), коммутатор ПТВ (КмПТВ), коммутатор управляющего слова (КмУС) и коммутатор данных. Коммутатор данных состоит из коммутатора записи в память (КмЗп) и коммутатора считывания (КмСч). Из схемы видно, что каждый из основных узлов КмОП представляет собой четыре модульных блока. Благодаря этому возможна одновременная работа всех четырех модулей с разными процессорами.

Схема приоритета принимает запросы на обмен и выстраивает очередь в соответствии с временем поступления запросов и приоритетом запросчиков. Блок временных диаграмм управляет запуском накопителя и отслеживает его занятость. При свободном модуле схема приоритета разрешает прием управляющего слова (19-разрядный адрес обращения и код операции) первого в очереди запроса, запускает блок ВРД и через КмПТВ выдает сигнал подтверждения соответствующему процессору.
Адрес и код операции через КмУС передаются в накопитель, коммутатор данных принимает число для записи в память или передает число из накопителя в линию связи. При записи числа в память блок коррекции и контроля формирует и передает в накопитель 8-разрядный код Хемминга записываемого числа; при считывании — исправляет одиночные ошибки и выдает сигнал аварии в случае обнаружения двойной ошибки.
Кроме обычных операций записи и считывания в ЭПП выполняются специальные операции для контроля аппаратуры секции, операция записи в регистр конфигурации и операция синхронизации.
Операция синхронизации и функционирование регистров конфигурации описаны ниже.
Устройство обмена с оперативной памятью. Устройство обмена с оперативной памятью является составной частью ЦП и осуществляет обмен информацией между ЦП и ОП. УООП имеет отдельный канал связи с каждой из восьми секций ОП и может обращаться в каждую секцию как с одиночными, так и с групповыми запросами.
При групповом запросе за одно обращение происходит обмен четырьмя словами. Время обращения по записи в память составляет для УООП около восьми тактов, время обращения по считыванию из памяти — около 20 тактов (обращение может быть задержано коммутатором ОП в случае занятости модуля памяти или конфликта по обращению с другим ЦП).
Запросы на обмен с ОП поступают из буфера коанд и буферной памяти на входные регистры УООП. Одновременно в УООП может храниться до трех запросов. УООП имеет внутреннее распараллеливание на два канала, что позволяет выставлять одновременно два запроса на обмен в разные секции ОП. Максимальная частота смены в канале — один запрос за восемь тактов. Таким образом, при групповых обращениях к памяти УООП обеспечивает темп обмена — одно слово за такт. Смена запросов в каналах происходит после получения сигналов ПТВ из КмОП. Считанная из ОП информация передается в БП или БК.
УООП контролирует информацию, поступившую из ОП, и принимает от КмОП сигналы контроля за прохождением обмена.
Для повышения темпа обмена при последовательном обходе адресов в УООП принята система размещения последовательных четверок адресов в разных модулях оперативной памяти. (Интерливинг внутри модулей обеспечивается аппаратурой секций ОП). Для этого старшие разряды адреса, определяющие номер модуля (секции) ОП, меняются местами с младшими разрядами адреса (рис. 10).
При исключении отдельных модулей из конфигурации операционная система не назначает их адреса. Наличие выключенного модуля делает невозможным интерливинг в данной секции.
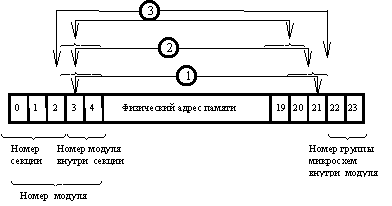
1 — интерливинг "два". Последовательные четверки адресов располагаются в двух смежных модулях памяти; 2 — интерливинг "четыре". Последовательные четверки адресов располагаются в четырех модулях одной секции; 3 — интерливинг "восемь". Последовательные четверки адресов располагаются в модулях двух смежных секций памяти.
Однако УООП реализует максимально возможный интерливинг для каждой области ОП. Необходимые преобразования адресов выполняются блоком преобразования адресов обращения на основе данных о состоянии поля памяти из регистра конфигурации (РКф) и адреса обращения.
Основное назначение системы ввода-вывода — передача фиксированных массивов информации между внешними устройствами и оперативной памятью в МВК “Эльбрус”. В состав вычислительной системы может входить от одного до четырех ПВВ и до 1023 периферийных устройств.
Процессор ввода-вывода представляет собой специализированный процессор со своей буферной памятью, арифметическими и логическими схемами и обеспечивает управление связью центральной системы с внешними устройствами. ПВВ максимально освобождает центральный процессор от рутинной работы по организации обменов, выполняет функции диспетчера ввода-вывода. Процессор ввода-вывода производит обмен с широким спектром внешних устройств асинхронно и независимо от центрального процессора.
Основу управляющей информации для ПВВ при выполнении операций обмена составляет карта работ, представляющая совокупность программных элементов (слов), расположенных в оперативной памяти системы.
Карта работ ввода-вывода. Карта работ содержит все необходимые сведения, позволяющие ПВВ произвести поиск пути к внешнему устройству, запуск внешнего устройства, передачу данных и запись в оперативную память результатов обмена. Карта работ предусматривает наличие связанной очереди заявок с требованиями на обмен к каждому внешнему устройству. ПВВ “укорачивает” эту очередь по мере выполнения заявок, а ЦП ее “удлиняют” по мере появления новых требований на ввод-вывод информации.
Заявка на ввод-вывод информации формируется ЦП в виде группы последовательно расположенных слов, в которых содержится необходимая управляющая информация для производства обмена, включая данные о передаваемом массиве информации и команду для внешнего устройства. Если к данному устройству имеется несколько заявок на обмен, то соответственно имеется столько же групп программных элементов, содержащих управляющую информацию.
Механизм очередей позволяет ПВВ последовательно обрабатывать требования на ввод-вывод в автоматическом режиме без участия ЦП. Для выполнения всего объема работ по вводу-выводу достаточно произвести однократный начальный пуск ПВВ со стороны ЦП.
Структура карты работ представлена на рис. 11. Программные элементы карты работ конструируются ОС в оперативной памяти при инициализации системы.
Знаком "*" помечены слова, в которых имеется семафорный бит.
В состав карты работ входят следующие элементы:
- базовая команда (БАК);
- таблица устройств (ТУС);
- таблица очередей (ТОЧ);
- дескриптор выполненных работ (ДВР);
- блоки управления вводом-выводом (БВВ).
Элементы карты работ БАК, ТУС, ТОЧ, ДВР могут размещаться в любых областях оперативной памяти системы, но с привязкой к определенному начальному адресу, который называется базовым адресом.
В ПВВ входят четыре регистра базовых адресов (БАБАК, БАТУС, БАТОЧ, БАДВР), содержимое которых определяет положение соответствующих элементов карты работ в оперативной памяти. Указанные базовые адреса могут быть изменены в процессе работы вычислительного комплекса. Для этого используются соответствующие команды изменения базовых адресов. Начальный адрес БВВ помещается в слове ТОЧ и в каждом конкретном случае может быть произвольным.
Базовая команда (БАК) — первый элемент карты работ, который считывается ПВВ из оперативной памяти системы по прерыванию от ЦП. В слове БАК размещается команда, которую должен выполнить ПВВ. Базовые адреса для БАК каждого ПВВ, входящего в состав одного вычислительного комплекса, различны, так что каждый ПВВ обращается только по “своему” базовому адресу. Для предотвращения конфликтных ситуаций между несколькими ЦП при одновременном их обращении к одному и тому же ПВВ в слове БАК имеется семафорный бит, который устанавливается в 1, в момент считывания БАК процессором ввода-вывода или центральным процессором. Установка семафорного бита запрещает обращение к данному слову БАК других ЦП. Установка семафорного бита в 0 производится ПВВ после того, как он произведет считывание из оперативной памяти слова БАК и расшифрует содержащуюся там команду.
Таблица устройств (ТУС) представляет собой последовательность слов, расположенных в оперативной памяти системы, начиная с базового адреса ТУС (БАТУС). Число слов в таблице устройств не превосходит 1024. Индексом для слова таблицы устройств является номер внешнего устройства (от 0 до 1023).
Каждое слово ТУС (кроме нулевого) содержит информацию о типе устройства, способе его подключения к ПВВ, фазе работы по обмену, о действиях, которые необходимо произвести по концу обмена, и т. д. Каждое слово ТУС имеет семафорный бит, запрещающий обращение к данному слову как ЦП, так и других ПВВ. Семафорный бит устанавливается в 1 после считывания слова ТУС центральным процессором или процессором ввода-вывода.
Таблица очередей (ТОЧ) представляет собой последовательность пар слов, расположенных в оперативной памяти системы, начиная с базового адреса ТОЧ (БАТОЧ). Число пар слов таблицы очередей равно числу внешних устройств в системе. Индексом каждой пары является удвоенный номер устройства (НУС), т.е. адрес каждой пары слов ТОЧ равен БАТОЧ + 2НУС. Наличие в адресе ТОЧ двух слов для каждого устройства определяется механизмом организации очередей запросов на обмен. Очередь заявок к каждому внешнему устройству формируется ОС при участии ЦП, а обрабатывается процессором ввода-вывода. Для выполнения этого условия, т. е. независимого доступа к очереди заявок со стороны ПВВ и ЦП, для каждого устройства отводятся два слова в ТОЧ. В первом слове содержится адрес первой заявки на обмен к данному устройству, т.е. начало очереди (НОЧ); во втором слове — адрес последней заявки к данному устройству, т.е. конец очереди (КОЧ).
Если к данному устройству не было заявок на обмен, то в поле адреса слов НОЧ и КОЧ записаны нули. С появлением первой заявки на ввод-вывод ЦП помещает адрес сформированной БВВ в слова НОЧ и КОЧ. По мере появления новых заявок ЦП изменяет содержимое адреса в слове КОЧ в соответствии с новой заявкой, без обращения к слову НОЧ.
Дескриптор выполненных работ (ДВР) представляет собой слово, расположенное в оперативной памяти системы по адресу БАДВР, ДВР предназначен для хранения связанной последовательности обработанных заявок, образующих очередь выполненных работ.
Очередь выполненных работ содержит все требования на ввод-вывод, обработанные ПВВ, включая заявки, при выполнении которых были зафиксированы сбои, т. е. очередь выполненных работ представляет собой смесь из законченных работ и данных об ошибках, связанных последовательно.
Очередь выполненных работ обрабатывается ОС в процессе выполнения рабочих программ, причем содержимое ДВР гасится, после чего ПВВ начинает создавать новую очередь. Все сбойные ситуации, входящие в очередь выполненных работ, анализируются для классификации содержащихся признаков сбоя и организации повторных требований на обмен.
Блоки управления вводом-выводом (БВВ) представляют собой требования на обмен для каждого внешнего устройства, которые формируются ОС при участии ЦП в виде групп слов, последовательно расположенных в оперативной памяти системы, начиная с адреса, указанного в слове НОЧ таблицы очередей.
Указанная последовательность слов содержит всю необходимую управляющую информацию для производства обмена. В состав БВВ входит семь слов:
- слово связи (СВ);
- слово левой работы (ЛР);
- дескриптор массива обмена (ДО);
- слово управления обменом (СО);
- слово периферийного устройства (СПУ);
- дескриптор результата (ДР);
- дескриптор результата устройства (ДРУ).
Слово связи указывает на следующий в очереди заявок блок ввода-вывода. В последнем блоке управления вводом-выводом слово связи равно нулю, что является признаком конца очереди.
Слово левой работы используется для выполнения заявок, связанных с очередью к i-му устройству, которые должны быть выполнены во время работы с очередью к j-му устройству.
Дескриптор массива обмена указывает адрес и разряды массива с точностью до байта. Массив всегда должен начинаться с начала слова.
Слово управления обменом содержит информацию, необходимую для работы канала, причем часть информации используется только в одних типах каналов и не используется в других.
СПУ, ДР и ДРУ специфичны для каждого типа внешних устройств.
Слово периферийного устройства содержит информацию, необходимую для работы внешнего устройства.
Дескриптор результата — это слово ПВВ, в которое записывается результат обмена канала с внешним устройством.
Дескриптор результата устройства записывается в БВВ, если обмен прошел со сбоем и содержит дополнительную информацию о сбое внешнего устройства.
Структура ПВВ. На рис. 12 представлена структурная схема ПВВ, включающая следующие устройства:
- устройство управления вводом-выводом;
- коммутатор ПВВ;
- пульт управления ПВВ;
- секция быстрых каналов для обмена с вычислительными устройствами (ВУ) высокого темпа обмена;
- секция стандартных каналов обмена с ВУ по интерфейсу ЕС ЭВМ;
- секция сканирования для обмена с ППД;
- блок имитатора памяти.
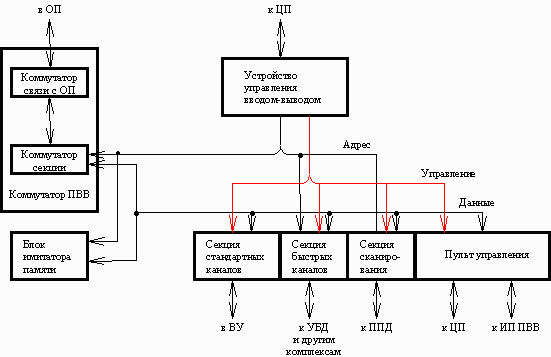
Процессор ввода-вывода выполняет следующие функции:
- принимает сигналы прерывания от ЦП;
- производит выборку командной информации из оперативной памяти и выполняет содержащуюся там команду;
- формирует информацию для управления запуском внешнего устройства;
- выбирает оптимальный путь обмена информацией;
- запускает внешнее устройство и производит передачу данных в соответствии с требованиями на обмен;
- производит запуск процессора передачи данных;
- завершает передачу данных и перестраивает очередь требований на обмен;
- обеспечивает работу в местном и центральном режимах в заданной конфигурации.
Конструктивно шкаф ПВВ состоит из блоков:
У, К, П, Б (2 шт.), С (2 шт.), НЛО и коммутатора ОП.
Устройство управления вводом-выводом (УВВ) является основным организующим звеном процесса обмена. УВВ организует выбор пути и передачу информации между внешними устройствами и оперативной памятью; формирует управляющие слова и передает их в каналы для запуска внешних устройств; сообщает ОС об окончании работы и результатах обмена, а также об обнаруженных в процессе обмена ошибках. Взаимодействие с ОС осуществляется через карту работ.
В состав УВВ входят:
- регистры базовых адресов для доступа к элементам карты работ;
- регистры рабочих слов для хранения информации о виде и состоянии работ, а также об адресах связи по памяти;
- стек активных каналов для хранения информации о работающих каналах;
- стек очередных работ для хранения стоящих на очереди невыполненных работ;
- стек окончаний для выбора номера канала, окончившего обмен, и завершения обслуживания заявки со стороны канала;
- регистры приема и выдачи рабочих слов, используемые для связи УВВ с коммутатором, каналами, секцией сканирования и пультом;
- регистр номера канала для хранения и выдачи номера канала в служебные секции;
- регистр номера устройств, содержащий номер запускаемого в данный момент устройства;
- сумматор, предназначенный для формирования адреса обращения в ОЗУ;
- адресный регистр — выходной регистр адреса обращения в ОЗУ;
- регистр кода операции, содержащий текущий код операции при обращении в ОЗУ.
Работа УВВ начинается либо по прерыванию, либо по окончании обмена с внешним устройством. При этом она выполняется логически завершенными процедурами, которые фактически являются запаянными подпрограммами организации обмена. Каждая из процедур считается не прерываемой до полного ее окончания. Если возникает ситуация запуска нескольких процедур, то выбирается старшая по приоритету.
Каждая из процедур представляет собой запаянную на триггерах временную диаграмму. В нужный момент времени при прохождении по диаграмме возникают стробирующие сигналы, управляющие передачей информации с регистра на регистр.
Коммутатор ПВВ предназначен для передачи потоков информации между секциями ПВВ и модулями ОП.
Коммутатор ПВВ состоит из коммутатора секций и коммутатора связи с ОП. Коммутатор секций предназначен для передачи информации от любой секции ПВВ к коммутатору связи с ОП и от коммутатора связи с ОП к любой секции ПВВ.
Пропускная способность коммутатора определяет максимальную производительность секций ПВВ — 30 Мбайт/с при тактовой частоте 260 нс и объеме передаваемой информации — 72 разряда.
В состав коммутатора входят следующие законченные функциональные узлы:
- канал прямой передачи (от секций ПВВ к ОП);
- канал обратной передачи (от ОП к секциям ПВВ);
- средства аппаратного контроля;
- схема формирования адресов холодной загрузки;
- средства индикации.
Работа коммутатора секций начинается с момента поступления заявки на обмен. Процесс обмена информацией по обоим направлениям происходит независимо, за исключением сбойных ситуаций в канале прямой передачи.
Пульт управления ПВВ расположен в блоке П и выполняет вспомогательные функции в составе ПВВ. Он не принимает непосредственного участия в обмене информацией между ОП и внешними устройствами.
Блок П предназначен для ввода ПВВ в одну из конфигураций вычислительного комплекса, начальной установки ПВВ и запуска системы, автоматического перезапуска системы, приема и выдачи прерываний центральным процессорам, а также для индикации состояния ПВВ.
Блок П состоит из следующих узлов: регистра конфигураций; регистра аварий; схемы выработки начальной установки и пуска; схемы инициализации; системы прерываний; таймера; системы индикации.
Регистр конфигурации предназначен для хранения данных о конфигурации устройств вычислительного комплекса и ввода в конфигурацию непосредственно процессора ввода-вывода. Кроме того, регистр конфигурации передает в блок К состояние модулей ОП для организации перекодировки адреса в случае неисправности одного модуля или более в секции ОП, а также для того, чтобы ПВВ знал стартовый модуль памяти.
Конфигурация ПВВ необходима для выяснения стартового ПВВ, а конфигурация ЦП — для защиты от прерываний тех ЦП, которые не входят в конфигурацию, а также для выдачи прерывания стартовому ЦП.
Регистр аварий служит для приема и хранения аварий от других модулей системы.
Схема выработки сигналов начальной установки ПВВ и сигнала ПУСК запускается по сигналам, приходящим от пульта оператора системы и инженерного пульта ПВВ.
Выработанные сигналы обеспечивают начальную установку всех блоков ПВВ и инициализацию всего вычислительного комплекса стартовым ПВВ либо автономный запуск в местном режиме. Система инициализации позволяет запустить вычислительный комплекс как в режиме перезапуска, так и в режиме холодной загрузки.
Схема инициализации вырабатывает стартовые прерывания в блок У, выдает команду для пуска устройства, управляющее слово канала и слово периферийного устройства.
Система прерываний выдает прерывания как центральным процессорам, так и блоку У. Если процессор ввода-вывода находится в автоматическом режиме, то прерывание от ПВВ выдается всем ЦП, находящимся в аналогичной конфигурации. В режиме загрузки прерывание от ПВВ выдается только младшему ЦП.
Таймер выдает сигналы, необходимые для работы каналов и блока У.
Система индикации передает информацию для индикации ее на инженерном пульте ПВВ.
Секция быстрых каналов предназначена для обмена с внешними устройствами, имеющими высокий темп обмена (до 4 Мбайт/с), а также для связи с другими комплексами в режиме межкомплексного обмена.
Связь между внешними устройствами и быстрыми каналами осуществляется через соответствующие устройства управления внешними устройствами (УВУ). К каждому каналу можно подключить только одно УВУ.
Блок быстрых каналов состоит из четырех отдельных каналов, обмен по которым осуществляется параллельно. Суммарная пропускная способность четырех каналов составляет не менее 16 Мбайт/с. При организации межкомплексного обмена канал одного вычислительного комплекса связан с каналом другого вычислительного комплекса. Образованный таким образом тракт передачи информации позволяет осуществить обмен между ОЗУ двух различных комплексов, минуя промежуточный носитель информации или сопрягающее устройство.
В режиме внутреннего обмена осуществляется передача информации из одной области памяти в другую через два канала одного блока. Этот режим удобен для организации тестового контроля аппаратуры ППВ отладочных тестов. Он позволяет перемещать массивы внутри оперативной памяти.
Секция стандартных каналов предназначена для обмена с широким классом внешних устройств, имеющих средний и низкий темп обмена (до 300 Кбайт/с). Связь между внешними устройствами и стандартными каналами осуществляется через контроллеры.
Конструктивно все стандартные каналы, входящие в ПВВ, объединены в два идентичных блока С1 и С2. К каждому каналу можно подключить несколько контроллеров последовательно.
Каждый блок С состоит из 16 каналов, обмен по которым осуществляется параллельно. Суммарная пропускная способность 16 каналов составляет не менее 1,6 Мбайт/с. Общий ресурс производительности блока С распределяется неравномерно между всеми каналами в зависимости от поступающих заявок. Это позволяет подключить к одному или нескольким каналам довольно быстрые устройства, в том случае если к остальным каналам подключены устройства с малым темпом обмена. Общее число внешних устройств на одном канале не должно превышать 16.
Блок имитатора памяти (БИП) предназначен для автономной настройки ПВВ при проведении пусконаладачных работ. Он позволяет имитировать режим обмена информацией для секций ПВВ без участия коммутатора и оперативной памяти.
Конструктивно БИП размещается в блоке К и состоит из четырех ячеек памяти и четырех ячеек управления.
БИП работает в двух основных режимах.
- обмена с видеотоном инженерного пульта;
- обмена с коммутатором секции ПВВ.
Секция сканирования, предназначенная для связи ПВВ с четырмя процессорами передачи данных, принимает управляющие слова от УВВ и передает их после загрузки команды ППД.
После загрузки команды ППД осуществляет обмен информации между ППД и коммутатором ОП. Конструктивно секция сканирования размещается в блоке НЛО.
Межкомплексный обмен. Средства межкомплексного обмена МВК “Эльбрус” обеспечивают обмен между двумя МВК через быстрые каналы ПВВ без участия промежуточной внешней памяти или какого либо адаптера. Для этой цели в быстром канале ПВВ и интерфейсе ввода-вывода реализован специальный режим работы, задаваемый управляющими полями карты работ и, в частности, блоком ввода-вывода.
Каждый тракт обмена использует по одному быстрому каналу ПВВ от каждого МВК и обеспечивает обмен в любом направлении в полудуплексном режиме. В соответствии с едиными принципами организации обменов в МВК “Эльбрус” для осуществления межкомплексного обмена используется общий для всей системы механизм очередей. Обмен через один тракт межкомплексного обмена осуществляется сеансами. Сеанс заключается в передаче из одного МВК в другой данных в соответствии с очередями заявок на обмен к псевдоустройствам (очереди БВВ к устройствам, номера которых отведены под межкомплексный обмен). Сеанс обмена состоит из тактов обмена. Один такт обмена соответствует обслуживанию пары заявок — по одной заявке из каждой очереди от двух взаимодействующих МВК: в одном МВК — заявка на прием информации, в другом МВК — заявка на выдачу. Переход от одного такта обмена (нормально завершенного) к следующему, если существует очередь БВВ, осуществляется аппаратно, без обращения к программным средствам.
Передача данных между каналом и УВУ в большинстве используемых интерфейсов ввода-вывода универсальных ЭВМ осуществляется по асинхронному принципу “запрос-ответ” (передача с квитированием). Темп обмена в тракте задается внешним устройством. В тракте межкомплексного обмена на базе быстрых каналов функцию задатчика в передаче с квитированием выполняет канал, осуществляющий запись в ОП.
Вопрос повышения скорости передачи в тракте межкомплексного обмена решается за счет применения в разработанных интерфейсах широкоформатной параллельной передачи со средствами ускорения (дополнительные линии идентификации). Дальность передачи обеспечивается специально разработанными для интерфейсов МВК усилителями-передатчиками. Эта фаза межкомплексного обмена в МВК “Эльбрус” отличается тем, что в результате ее выполнения каналы обмениваются информацией состояния, что приводит к унификации обработки результатов такта межкомплексного обмена и обычной операции обмена.
Система телеобработки. Применение вычислительных систем в различных областях, в том числе для управления сложными объектами, показало, что удовлетворительных показателей эффективности можно достичь только при обеспечении непосредственной связи между местами генерации информации, вычислительной системой и объектами управления. Осуществление этого невозможно без использования каналов связи. Под системой телеобработки принято понимать совокупность аппаратных и программных средств, предназначенных для обработки на вычислительных системах данных, передаваемых по каналам связи.
Традиционные методы подсоединения линий связи предусматривают подключение мультиплексоров передачи данных (МПД) к мультиплексному каналу ЕС ЭВМ. Для расширения функций МПД в его состав вводится микропроцессор для программной обработки принимаемых и отправляемых сообщений. Введение программируемости МПД позволяет снизить нагрузку на ЦП за счет реализации в МПД функции повышения достоверности передаваемых данных, установления соединений по коммутируемым каналам связи, индикации состояний МПД и каналов связи.
Дальнейшее развитие идеи использования программируемого МПД приводит к использованию связного процессора или процессора передачи данных (ППД), управляемого собственной ОС. Применение ППД является отличительной особенностью МВК и подтверждает общую тенденцию повышения эффективности вычислений за счет организации работы на нескольких специализированных параллельно работающих модулях.
Информация и сигналы управления в интерфейсе связи с ППД передаются посредством 132 линий: 15 линий — для передачи сигналов управления от ПВВ к ППД; 40 линий — для передачи сигналов управления и адреса обращения в память от ППД к ПВВ; 77 линий — для использования в полудуплексном режиме.
Принципы подключения ППД к ПВВ поясняются схемой, показанной на рис. 13.
Интерфейс обеспечивает передачу как данных, так и приказов ППД путем выполнения специальной команды в ПВВ. Инициализация тракта обмена предшествует выдаче приказов на ППД. Открытие маски ППД выполняется специальной командой установки маски конфигурации (МКф) из системы команд ПВВ. Для передачи в ППД при выполнении команды групповой рассылки сигналов в ПВВ допускается использование трех приказов: ПУСК, ВНИМАНИЕ, ОСТАНОВ.
Приоритет между различными ППД по выполнению операций обмена осуществляется поддержанием дисциплины FIFO в отношении заявок на обмен от этих ППД. Введение любой другой дисциплины обслуживания привело бы к некоторой дискриминации в отношении ППД с меньшим относительным приоритетом.
Передача данных между секцией сканирования и любым ППД осуществляется всегда по инициативе ППД, присылающего сигнал запроса на обмен. Секция сканирования отвечает выдачей сигнала готовности, подтверждающего возможность выполнения обмена. Далее начинается фаза обмена и ППД передает адрес, код операции, число (в случае записи в ОП) и сопровождает все это соответствующим идентификатором. Секция сканирования после выполнения операции с памятью выдает в ППД сигнал завершения работы, сопровождаемый (в случае считывания) числом из памяти.
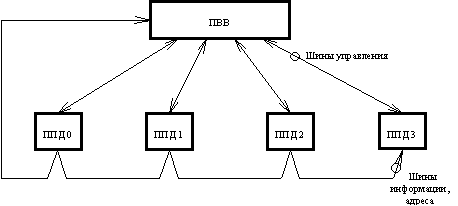
5. Внутрикомплексное взаимодействие
Модульный тип построения комплекса требует гибкой аппаратно-программной поддержки, способной разрешить возникающие конфликты между модулями системы либо восстановить работоспособность комплекса.
Конфигурация МВК. В МВК “Эльбрус-2” наряду с работой всех модулей в рамках единой системы предусмотрена возможность образования до четырех независимых подсистем (конфигураций). Выделение некоторой совокупности модулей в независимую подсистему имеет логический характер и не требует физической перекоммутации. С этой целью в аппаратуру центральных модулей МВК (ЦП, ОП, 11ВВ) введены специальные регистры (регистры конфигурации), хранящие информацию о составе подсистемы. Содержимое этих регистров маскирует обращения от других модулей при внутрикомплексных взаимодействиях.
Регистры конфигурации устанавливаются аппаратным и программным способами.
При инициализации комплекса модули по специальным шинам обмениваются именами собственных конфигураций и по совпадению имен формируют свои регистры конфигурации. Имя собственной конфигурации задается с местного пульта управления либо с пульта оператора комплекса.
В процессе функционирования содержимое регистров конфигурации изменяется программно операционной системой либо аппаратно системой автоматической реконфигурации при возникновении аварий.
Наличие гибкой аппаратно-программной системы формирования логически независимых конфигураций в рамках единого комплекса позволяет обеспечить скрытую от пользователей реконфигурацию МВК, например, вывод в “ремонтную” конфигурацию произвольного набора модулей для ремонта или текущей профилактики, а также возврат модулей в “рабочую” конфигурацию.
Аппаратная поддержка механизма семафоров. В МВК “Эльбрус” задача может порождать несколько процессов, Например, операционная система, обслуживая одновременно большое число пользователей и работая на их стеках, выступает в качестве одной задачи со многими параллельными процессами.
Участок программы, использующий (считывающий или модифицирующий) общие для нескольких процессов данные, называется критической секцией.
В качестве средства синхронизации параллельных процессов при доступе к общим данным используются семафоры — служебные слова, сопровождающие массивы данных и располагающиеся в оперативной памяти.
Если один или несколько процессов считывают общие данные, то никакой другой процесс не должен их модифицировать. В семафоре предусмотрено поле, содержащее информацию о числе процессов, пользующихся общими данными. Очередной процесс перед считыванием наращивает значение этого поля, а при выходе из критической секции — уменьшает его на 1. Ненулевое значение поля означает что семафор “закрыт по считыванию”.
Процесс, который должен модифицировать общие данные, “закрывает семафор по записи”, проставляя в нем соответствующий признак. Попытка закрыть по записи уже “закрытый” семафор приводит к прерыванию, конфликт разрешается операционной системой. После модификации общих данных процесс “открывает” семафор.
Так как к семафору может одновременно обращаться несколько процессов, работа с ним, в свою очередь, требует синхронизации. Для этого используется синхробит, входящий в состав семафорного слова. Команда, считывающая семафор, одновременно автоматически перезаписывает его в оперативную память с синхробитом, равным 1 (операция синхросчитывания). Синхробит сбрасывается записью модифицированного семафора. Процесс, считавший семафор, который уже обрабатывается, обязан дождаться обнуления “синхробита и только после этого начинать модификацию.
Межпроцессорное взаимодействие. Связь процессорных модулей, находящихся в одной конфигурации, реализована через механизм прерываний.
В соответствии с набором функциональных модулей МВК можно выделить взаимодействие типа ЦП — ЦП и ЦП — ПВВ.
Взаимодействие ЦП—ЦП. Все ЦП равноправны в МВК и выполняют задания из общей для всех процессоров очереди работ, пополняемой ОС. Один из ЦП, выполняя функции программного диспетчера, выдает другим ЦП сигналы прерывания и выходит на операцию ожидания реакции. Другие ЦП, получив сигнал прерывания, выдают сигнал подтверждения (ответа) процессору-диспетчеру и также выходят на операцию ожидания дальнейших инструкций. Процессор-диспетчер, получив требуемое число подтверждений, организует синхронную работу всех ЦП системы.
Для реализации данного протокола обмена в ЦП предусмотрены следующие команды:
- “прервать процессор” — выдается сигнал прерывания всем процессорам, указанным в операнде-маске;
- “ответ ЦП” — выдается сигнал ответа;
- “ждать” — ЦП находится в состоянии ожидания, пока не поступят сигналы ответа от всех процессоров, указанных в операнде.
Взаимодействие ЦП—ПВВ. ЦП, выполняя программу ОС, формирует очередь заявок к заданному внешнему устройству. Если очередь заявок не пуста и, следовательно, выполняется или ждет выполнения, достаточно нарастить ее очередной заявкой. Если очередь заявок пуста, то необходимо выдать в ПВВ сигнал прерывания от ЦП. Процессор ввода-вывода анализирует заявку и начинает обмен. По окончании обмена ПВВ перемещает заявку в очередь готовых работ без прерывания ЦП; прерывание ЦП со стороны ПВВ производится только в том случае, если обмен не может быть выполнен по тем или иным причинам.
Система автоматической реконфигурации. Одним из механизмов, обеспечивающих “живучесть” комплекса, является система автоматической реконфигурации и перезапуска при сбоях и отказах (CAP). Эта система включает в себя специальную аппаратуру, распределенную по модулям МВК, системные шины, а также программные средства, входящие в состав ОС.
Аппаратно выполняются следующие действия:
- обнаружение аварии в модуле, дифференцирование ее по типу, сохранение диагностической информации и приостановка работы аварийного модуля;
- передача информации об аварии по специальным шинам в другие модули;
- обработка сигналов аварии, приходящих от других модулей, и исключение (если требуется) аварийного модуля из конфигурации;
- системная реакция на аварию — либо запуск специальных процедур ОС, либо автоматический перезапуск комплекса (в зависимости от типа аварии).
Программно выполняются следующие действия:
- сбор и обработка диагностической информации аварийного модуля;
- попытка вернуть его в рабочую конфигурацию в предположении, что авария имеет сбойный характер;
- сохранение в системном журнале информации об аварии.
Аварии модулей МВК подразделяются на синхронные и асинхронные.
Синхронность аварии подразумевает возможность идентификации команды, на которой произошла авария, а также сохранение состояния вычислительного процесса на этот момент. Таким образом, команда, вызвавшая синхронную аварию, может быть повторена, и если авария не имеет константного характера, то вычисления могут быть продолжены. В МВК “Эльбрус-2” синхронность аварии удается обеспечить только в одном типе модулей — центральном процессоре.
При возникновении асинхронной аварии вычислительный процесс нарушается необратимо. Поэтому возобновить вычисления можно с контрольной точки либо с начала.
В CAP предусмотрены различные реакции на разные типы аварий.
Возникновение асинхронной аварии на процессе пользователя ведет к автоматическому исключению неисправного модуля из конфигурации и запуск процедуры ОС, обрабатывающей аварийную ситуацию и определяющей дальнейшее течение аварийного процесса (аварийное завершение или перезапуск). Остальные пользователи при этом “не чувствуют” аварийной работы. Исключение составляет случай, когда в конфигурации представлен лишь один модуль некоторого типа. Возникновение в нем аварии приводит к перезапуску всего комплекса.
Возникновение асинхронной аварии на процессе ОС всегда завершается перезапуском комплекса.
Одиночные синхронные аварии “не рассматриваются” CAP, и только в случае многократного (более 16 раз) повторения на одном и том же процессе они переводятся в разряд асинхронных и обрабатываются, как описано выше.
Таким образом, система автоматической реконфигурации и перезапуска в совокупности с другими средствами позволяет, во-первых, в большинстве случаев сделать незаметным для пользователей процесс текущего обслуживания комплекса, во-вторых, с высокой надежностью обеспечить решение крупных научно-технических задач или счет в реальном масштабе времени.
