
Система CRAY T3D (США)
-
Interconnect Network
-
Processing Element Nodes
-
I/O Gateways
3. Processing Element Nodes
Узлы элементов обработки выполняют все программные инструкции и хранят системные данные. После описания нумерации обрабатывающих элементов (PE) в этом разделе описываются физические узлы и компоненты узла обрабатывающего элемента.
Нумерация PE
В зависимости от контекста PE идентифицируется одним из трех типов чисел: физическим, логическим или виртуальным. Все три типа чисел состоят из бита PE, который определяет, является ли PE PE 0 или PE 1 в узле, и поля, содержащего номер узла или координаты узла.
Физический номер PE
Каждому PE в системе CRAY T3D присваивается уникальный номер, который указывает, где PE физически расположен в системе. Этот номер является физическим номером PE.
Схема поддержки в каждом PE содержит регистр, называемый физическим регистром PE. Когда печатная плата помещается в системный шкаф, оборудование автоматически устанавливает биты физического регистра PE, чтобы указать, где PE находится в шкафу.
Логический номер PE
Не все физические PE в системе CRAY T3D являются частью логической конфигурации системы CRAY T3D. Например, система CRAY T3D с 512 PE содержит 520 физических PE (не включая PE в шлюзах ввода-вывода). Из этих 520 PE 512 PE используются в логической системе, а 8 PE (в 4 резервных узлах PE) используются в качестве резервных PE.
Каждому физическому PE, используемому в логической системе, назначается уникальный логический номер PE. Логический номер PE определяет, где в логической системе узлов находится PE.
Логические узлы образуют трехмерную матрицу узлов. Например, на рисунке 2 показаны логические узлы PE для системы CRAY T3D с 128 PE. Хотя система фактически содержит 68 физических узлов PE, в логической системе используются только 64 узла. Остальные 4 запасных физических узла физически подключены к межсоединительной сети, но им не присвоены номера логических узлов.
Этот тип конфигурации позволяет запасному узлу логически заменить отказавший узел. Когда это происходит, резервный узел получает логический номер, а отказавший узел не получает новый номер логического узла.
Например, если логический узел Z = 0 Y = 2 X = 3 не работает должным образом, физический узел, назначенный этому номеру, может быть удален из логической системы. Затем запасному узлу присваивается номер логического узла Z = 0 Y = 2 X = 3, а отказавший узел не получает номер логического узла. Затем информация перезаписывается в справочную таблицу тегов маршрутизации каждого узла.
Таблица поиска тега маршрутизации содержит информацию, которую каждый узел использует для создания тега маршрутизации в заголовке пакета. Поскольку номер логического узла может соответствовать любому из физических узлов, оборудование в узлах не может использовать номер логического узла для маршрутизации данных от одного узла к другому.
Каждый узел PE в системе CRAY T3D использует таблицу поиска для получения тега маршрутизации. Схема в узле вводит номер логического узла в справочную таблицу тегов маршрутизации. Затем таблица поиска тегов маршрутизации предоставляет тег маршрутизации для пакета (см. Рисунок 1). Тег маршрутизации направляет пакет от физического узла-источника к физическому узлу назначения.

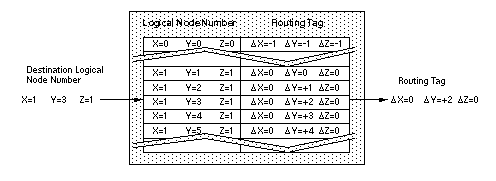
Рисунок 1. Поисковая таблица тегов маршрутизации для логического узла X = 1, Y = 1, Z = 1 <

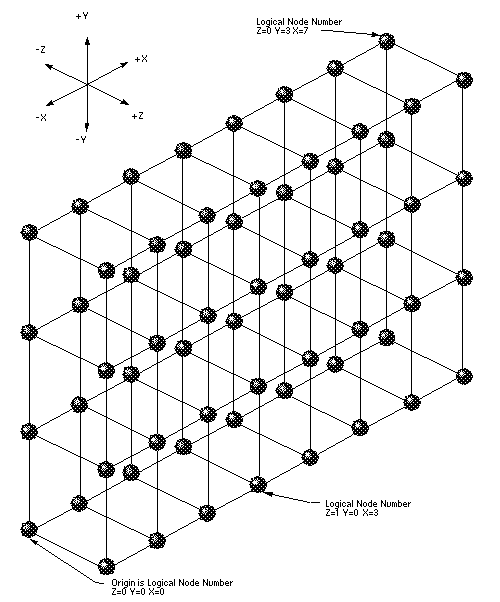
Рисунок 2. Логические номера узлов.
Виртуальный номер PE
Когда приложение MPP запускается, вспомогательное программное обеспечение, работающее в хост-системе, определяет ресурсы, необходимые для приложения, и создает раздел для запуска приложения. Раздел - это группа PE и часть назначенных ресурсов синхронизации барьера. к одному приложению. (Дополнительная информация о барьерной синхронизации представлена далее в этом разделе.) Приложение использует виртуальные номера PE для ссылки на PE в разделе.
Есть два типа разделов: раздел операционной системы и раздел оборудования. В разделе операционной системы, когда приложение передает данные между PE, операционная система должна участвовать в передаче. Операционная система преобразует виртуальные номера PE, используемые приложением, в логические номера PE.
В аппаратном разделе, когда приложение передает данные между PE, операционная система не участвует в передаче. Оборудование в каждом узле PE преобразует виртуальные номера PE, используемые приложением, в логические номера PE. Номер виртуального PE состоит из двух частей: номер виртуального узла и бит PE. Номер виртуального узла находится в диапазоне от 1 до 10 битов и указывает, в каком узле обрабатывающего элемента в аппаратном разделе находится PE. Бит PE указывает, является ли PE PE 0 или PE 1 в узле.
Номер виртуального узла имеет от 0 до 3 битов, назначенных для измерения X, от 0 до 4 битов, назначенных для измерения Y, и от 0 до 3 битов, назначенных для измерения Z. Назначая биты номера виртуального узла соответствующим размерам, программное обеспечение упорядочивает виртуальные узлы в одну из нескольких форм. Например, трехбитный номер виртуального узла означает, что в аппаратном разделе восемь узлов. Эти узлы могут иметь одну из 10 форм.
В таблице 1 перечислены возможные формы узлов для трехбитового номера виртуального узла. Для каждой формы количество узлов в каждом измерении ограничено степенью двойки (1, 2, 4, 8, 16 и т. Д.).

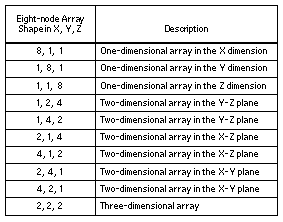
Таблица 1. Формы разделов с восемью узлами
На рисунке 3 показаны три из восьми узловых форм разделов в системе CRAY T3D на 128 PE.

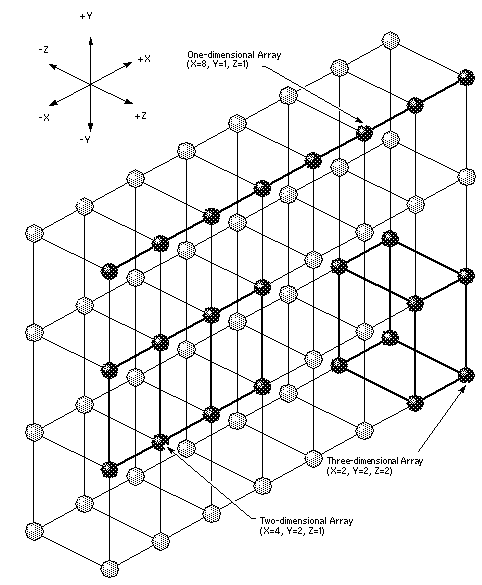
Рис. 3. Три формы разделов на 8 узлов в системе CRAY T3D на 128 PE
В качестве примера виртуальных номеров PE на рисунке 4 показан двумерный раздел из восьми узлов, содержащий 8 узлов. Каждый узел в разделе обозначается трехразрядным номером виртуального узла, показанным на рисунке 4.

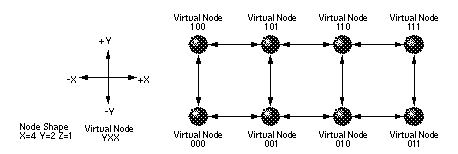
Рисунок 4. Номера виртуальных узлов двумерного массива.
Этот двумерный массив из восьми узлов может фактически соответствовать одному из многих двумерных массивов из восьми узлов в логической системе. Например, на рисунке 5 показаны два примера того, как этот двумерный массив может быть помещен в логическую систему узлов в системе CRAY T3D с 128 PE.
Номер виртуального узла не всегда соответствует одному и тому же номеру логического узла. Например, на рисунке 5 показано, как виртуальный узел Y = 1 X = 2 с рисунка 4 может соответствовать либо номеру логического узла Z = 1 Y = 2 X = 2, либо номеру логического узла Z = 1 Y = 3 X = 6.

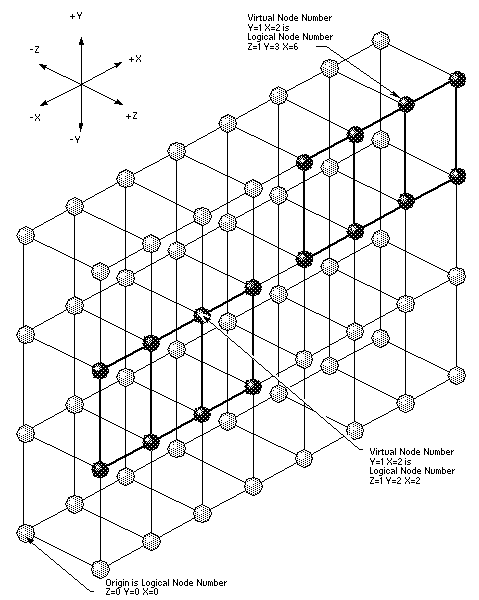
Рисунок 5. Виртуальные и логические номера узлов.
Физические узлы
Физически каждый узел элемента обработки располагается на половине печатной платы в системном шкафу CRAY T3D (см. Рисунок 6). Интегральные схемы над пунктирной линией используются для компонентов одного узла обрабатывающего элемента. Интегральные схемы под пунктирной линией используются для компонентов другого узла элемента обработки.

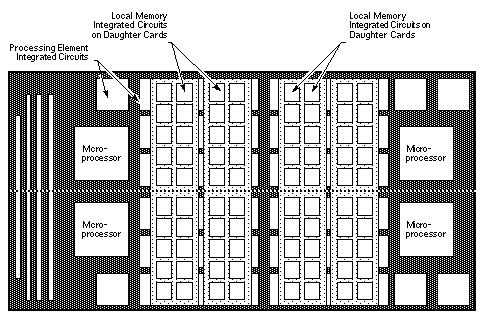
Рисунок 6. Печатная плата узла обрабатывающего элемента.
Компоненты
Узел элемента обработки состоит из четырех компонентов: двух PE, BLT и сетевого интерфейса (см. Рисунок 7).

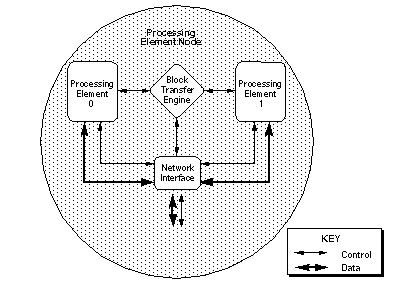
Рисунок 7. Узел элемента обработки.
На рисунке показана функциональная блок-схема компонентов в узле обрабатывающего элемента. В следующих подразделах описаны эти компоненты.

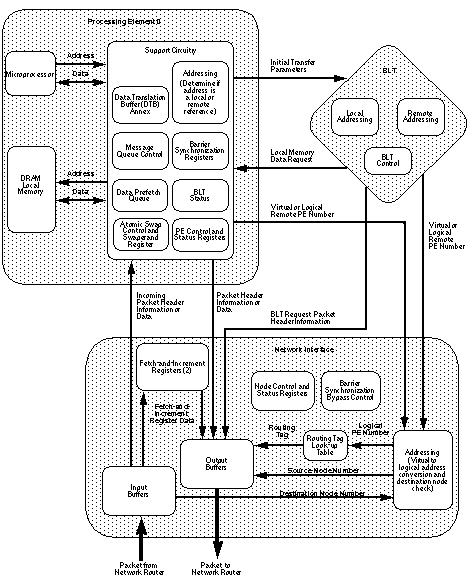
Рисунок 8. Функциональная блок-схема узла элемента обработки.
Элементы обработки
Каждый узел элемента обработки содержит два PE: PE 0 и PE 1. Каждый PE содержит микропроцессор, локальную память и вспомогательные схемы
.
Микропроцессор
Микропроцессор представляет собой 64-разрядный микропроцессор компьютера с сокращенным набором команд (RISC), разработанный Digital Equipment Corporation. Микропроцессор содержит центральный блок управления, целочисленный исполнительный блок, исполнительный блок с плавающей запятой, блок генерации адресов и интерфейс шины, кэш-память данных и кэш-память команд (см. Фиг.9). В следующих параграфах описывается каждый из этих компонентов.

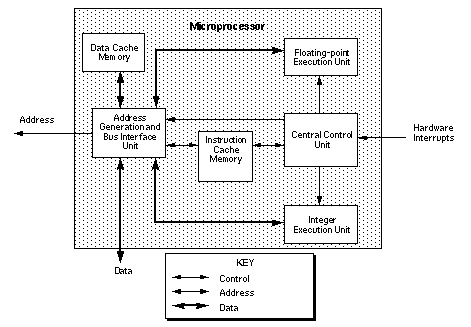
Рисунок 9. Микропроцессор.
Центральный блок управления выдает инструкции целочисленному исполнительному блоку, исполнительному блоку с плавающей запятой, а также блоку генерации адреса и интерфейса шины. Центральный блок управления также получает сигналы аппаратного прерывания от внешней цепи защитного заземления. Эти прерывания включают прерывания барьерной синхронизации, прерывания обмена сообщениями, прерывания BLT и прерывания ошибок.
Блок целочисленного исполнения выполняет целочисленные операции с 64-битными целочисленными регистрами. Целочисленные операции включают арифметические операции, операции сравнения, логические операции и операции сдвига. Всего имеется 32 целочисленных регистра.
Блок выполнения с плавающей запятой выполняет операции с плавающей запятой в 64-битных регистрах с плавающей запятой. Эти операции включают арифметические инструкции IEEE, а также инструкции для выполнения преобразований между числами с плавающей запятой и целыми числами. Всего 32 регистра с плавающей запятой.
Блок генерации адресов и шинного интерфейса генерирует адреса памяти и управляет данными и управляющей информацией. Схема генерации адреса преобразует виртуальный адрес, который она получает от компилятора, в адресную информацию, используемую схемой поддержки в PE. Схема интерфейса шины отвечает на инструкции чтения или записи для кэша данных, кэша инструкций и шины данных.
Кэш-память данных - это небольшая высокоскоростная память с произвольным доступом, в которой временно хранятся часто или недавно используемые данные. Кэш-память данных является внутренней по отношению к микропроцессору и хранит 256 32-байтовых строк (четыре 64-битных слова в строке) данных (см. Рисунок 10).

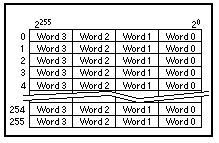
Рисунок 10. Организация кеш-памяти данных и кэша инструкций.
Кэш-память инструкций работает аналогично кэш-памяти данных, но хранит инструкции. Кэш-память инструкций также является внутренней по отношению к микропроцессору и хранит 256 32-байтовых строк данных.
Микропроцессор также выполняет обнаружение и исправление ошибок. После получения 128 бит данных и 28 контрольных бит от схемы PE микропроцессор генерирует новый набор контрольных битов. Если новый набор контрольных битов не идентичен исходному набору контрольных битов, 1 или более системных данных или исходных контрольных битов изменили значение во время передачи данных.
Если значение изменилось только на 1 бит, аппаратное обеспечение микропроцессора исправляет значение неправильного бита. Если значение изменилось более чем на 1 бит, микропроцессор прерывается.
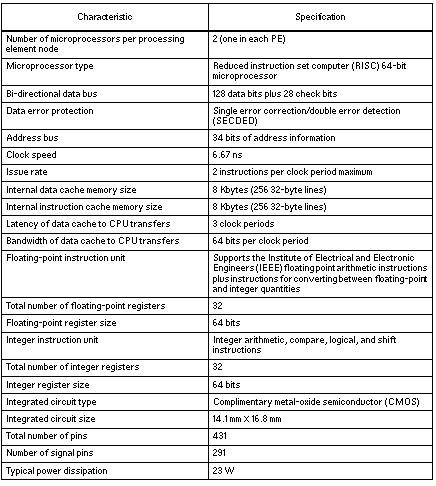
Каждый микропроцессор представляет собой 431-контактную интегральную схему решетчатой матрицы (PGA) (снова см. Рисунок 6). В таблице 2 перечислены характеристики микропроцессора.

Таблица 2. Технические характеристики микропроцессора
Локальная память
Каждый PE содержит локальную память. Локальная память состоит из динамической памяти с произвольным доступом (DRAM), в которой хранятся системные данные. Путь данных с низкой задержкой и высокой пропускной способностью соединяет микропроцессор с локальной памятью в PE.
Системные данные хранятся в физически распределенной логически разделяемой памяти. Память распределена физически, потому что каждый PE содержит локальную память. Память логически разделяется, потому что любой микропроцессор может получить доступ к данным в локальной памяти любого PE, не задействуя микропроцессор в этом PE.
На рисунке 11 показано физическое распределение памяти в системе CRAY T3D с 256 PE. В локальной памяти каждого PE хранится заданное количество 64-битных слов (представленных переменной m на рисунке 11). Размер локальной памяти зависит от типа интегральных схем DRAM, используемых в системе.

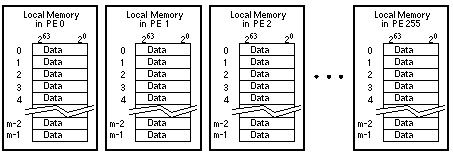
Рисунок 11. Физическое распределение памяти.
Общий размер разделяемой памяти - это размер локальной памяти в одном PE, умноженный на общее количество PE в системе. Например, система CRAY T3D с 512 PE, каждый с 2 мегабайтами локальной памяти, имеет общую системную память 1 гигабайт (8 гигабайт).
Каждый микропроцессор использует адресацию памяти, которая ссылается на любое слово в общей памяти. Этот адрес, виртуальный адрес, изначально создается компилятором программы. Виртуальный адрес преобразуется микропроцессором и другими компонентами в узле элемента обработки в номер логического узла, номер PE и смещение адреса.
Локальная память состоит из интегральных схем DRAM, установленных на печатных платах дочерних плат. Дочерние платы DRAM подключаются к печатной плате PE и располагаются наверху интегральных схем, используемых в PE (снова обратитесь к рисунку 6 и рисунку 12).

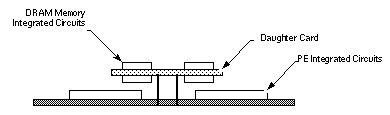
Рисунок 12. Печатная плата PE, вид сбоку.
В таблице 3 перечислены характеристики локальной памяти.

Таблица 3. Характеристики локальной памяти
Схема поддержки
Схема поддержки расширяет функции управления и адресации микропроцессора. Эти функции включают:
- Интерпретация адресов
- Читает и пишет
- Предварительная выборка данных
- Обмен сообщениями
- Барьерная синхронизация
- Получить и увеличить
- Положение дел
- Address interpretation
- Reads and writes
- Data prefetch
- Messaging
- Barrier synchronization
- Fetch and increment
- Status
Интерпретеция адреса (Address Interpretation)
В системе CRAY T3D адресные выводы микропроцессора не обращаются напрямую к физической памяти. Вместо этого вспомогательная схема в PE интерпретирует адрес и направляет данные между микропроцессором и либо локальной памятью, регистрами с отображением памяти, либо памятью в удаленном PE.
Схема поддержки использует часть адреса, сгенерированного микропроцессором, в качестве индекса в таблице из 32 записей, называемой приложением DTB. Каждая запись в приложении DTB содержит виртуальный или логический номер PE и код функции. Номер PE - это номер PE назначения. Код функции указывает, какой тип функции памяти будет выполнять вспомогательная схема.
Схема поддержки сравнивает номер PE, полученный от приложения DTB, с номером PE, который содержит схему поддержки. Если они совпадают, микропроцессор обращается к локальной памяти. Если они не совпадают, микропроцессор адресует память в другом PE.
Когда микропроцессор запрашивает передачу данных в локальной памяти, схема поддержки использует адрес микропроцессора в качестве смещения адреса для данных в локальной памяти. Затем схема поддержки передает данные между микропроцессором и локальной памятью.
Когда микропроцессор запрашивает передачу данных с удаленной памятью, схема поддержки отправляет номер удаленного PE вместе со смещением адреса и управляющей информацией в сетевой интерфейс для использования в заголовке пакета запроса.
Когда микропроцессор обращается к регистру в схеме поддержки, схема поддержки направляет информацию в соответствующий регистр. В некоторых случаях вспомогательная схема также выполняет функцию, связанную с регистром.
Чтение (Reads)
Операции чтения передают данные из системной памяти в регистр микропроцессора. В зависимости от типа операции чтения микропроцессор может также обновлять информацию в кэше данных.
После получения информации об адресе и запросе цикла от микропроцессора, схема поддержки извлекает код функции и номер PE из записи в приложении DTB. Значение кода функции определяет, какую операцию чтения выполняет схема поддержки. Существует два основных типа операций чтения: некэшируемое чтение и кэшированное чтение.
Во время некэшируемых операций чтения микропроцессор не помещает копию считанных данных в кэш данных. Во время кэшированного чтения микропроцессор помещает копию прочитанных данных в кэш данных. Кэшированные операции чтения могут использоваться для уменьшения задержки последующих операций чтения по указанным адресам памяти. Если данные в кэше данных действительны, микропроцессор считывает данные из кэша данных, а не из системной памяти.
Во время операций чтения некэшируемой памяти, когда вспомогательная схема передает считанные данные микропроцессору, вспомогательная схема сигнализирует микропроцессору не обновлять строку в кэше данных. Существует два типа некэшируемых операций чтения: обычное некэшируемое чтение и некэшируемое чтение атомарной подкачки.
Обычные некэшируемые операции чтения передают данные из памяти в регистр микропроцессора без обновления кэша данных. Некэшируемые операции чтения атомарного свопа передают 64-битное слово из памяти в микропроцессор, а затем передают другое 64-битное слово в то же место в памяти в неделимой операции.
Перед тем как инициировать операцию атомарного свопа, микропроцессор загружает 64-битное слово в регистр, называемый регистром подкачки. Во время операции атомарного свопа вспомогательная схема передает слово из памяти в микропроцессор, а затем передает слово из регистра подкачки в ту же ячейку памяти.
Во время кэшированных операций чтения, когда вспомогательная схема передает считанные данные микропроцессору, вспомогательная схема сигнализирует микропроцессору об обновлении строки в кэше данных. Существует три типа кэшированных операций чтения: обычное кэшированное чтение, кэшированное атомарное чтение подкачки и кешированное упреждающее чтение.
Нормальное кэшированное чтение и кэшируемое чтение атомарного свопа работают так же, как некэшируемое нормальное чтение и некэшируемое чтение атомарного свопа, за исключением того, что при передаче данных на микропроцессор схема поддержки сигнализирует микропроцессору об обновлении строки в кэше данных.
Кэшированные опережающие чтения используются, чтобы скрыть задержку чтения из локальной памяти. В следующих абзацах описывается кэшированное упреждающее чтение.
Схема поддержки содержит этап чтения из локальной памяти. После того, как схема поддержки выполняет операцию опережающего чтения в кэше, этап чтения из локальной памяти буферизует блок данных из четырех слов (или выборки инструкций), считанный из локальной памяти. Когда микропроцессор выполняет кэшируемую или некэшируемую операцию чтения любого типа (кроме атомарных свопов) с адресом, который соответствует буферизованному блоку данных, данные передаются из этапа чтения локальной памяти в микропроцессор. Это действие предотвращает доступ схемы поддержки к памяти DRAM для извлечения блока данных и уменьшает задержку для операции чтения.
Во время кэшированной операции упреждающего чтения схема поддержки извлекает блок данных из локальной памяти (или на этапе чтения из локальной памяти). Затем схема поддержки отправляет блок данных в микропроцессор и сигнализирует микропроцессору об обновлении кэша данных.
Сразу после отправки данных в микропроцессор схема поддержки извлекает следующий последовательный блок данных из локальной памяти и буферизует данные на этапе чтения локальной памяти схемы поддержки. Данные, буферизованные в схеме поддержки, остаются в схеме поддержки до тех пор, пока не будет выдана команда барьера памяти или пока не произойдет операция чтения данных или инструкции из другого адреса локальной памяти.
Запись (Writes)
Операции записи передают данные из микропроцессора в системную память. Чтобы инициировать операцию записи, микропроцессор предоставляет схеме поддержки адрес и информацию о запросе цикла. Затем микропроцессор может продолжить выдачу программных инструкций, пока вспомогательная схема завершает операцию записи.
После получения адреса и информации запроса цикла от микропроцессора, схема поддержки извлекает код функции и номер PE из записи в приложении DTB. Затем схема поддержки проверяет значение номера PE, считанного из приложения DTB. Если номер PE установлен на локальный PE, схема поддержки записывает до четырех 64-битных слов в локальную память. Если номер PE установлен на удаленный PE, схема поддержки создает пакет запроса записи, который содержит до 4 слов данных, и отправляет этот пакет запроса удаленному PE.
После создания пакета запроса записи схема поддержки увеличивает счетчик (называемый счетчиком невыполненных запросов на запись), который подсчитывает количество пакетов запроса записи, созданных и отправленных удаленным PE. После получения пакета ответа на запись поддерживающая схема в PE, запросившая операцию записи, уменьшает счетчик невыполненных запросов на запись. Это действие завершает операцию записи.
Предварительная выборка данных (Data Prefetch)
По запросу микропроцессора схема поддержки выполняет операцию предварительной выборки данных. Операция предварительной выборки данных передает одно 64-битное слово данных из памяти в удаленном PE в очередь предварительной выборки данных, которая находится в локальной схеме поддержки PE.
Микропроцессор инициирует операцию предварительной выборки данных, когда он встречает инструкцию предварительной выборки в программе. Программист может поместить команду предварительной выборки на несколько инструкций перед командой, которая фактически использует данные предварительной выборки.
При выдаче команды предварительной выборки микропроцессор сигнализирует схеме поддержки, что следующая передача данных является операцией предварительной выборки. После того, как микропроцессор выдает команду предварительной выборки, микропроцессор продолжает выполнение других программных инструкций.
Схема поддержки собирает информацию для пакета запроса чтения с предварительной выборкой и отправляет информацию удаленному PE по межсоединительной сети. После получения пакета запроса схема поддержки в PE-адресате создает пакет ответа на чтение с предварительной выборкой, который содержит слово данных и указывает, что данные являются ответом с предварительной выборкой. Схема поддержки в удаленном PE затем отправляет ответный пакет в локальный PE по межсоединительной сети.
Схема поддержки в локальном PE принимает пакет ответа предварительной выборки и сохраняет слово данных в очереди предварительной выборки данных. Когда микропроцессор выдает команду, которая использует данные, микропроцессор считывает данные из очереди предварительной выборки данных вместо того, чтобы создавать пакет запроса чтения и ждать ответа.
Очередь предварительной выборки данных хранит максимум 16 слов. Микропроцессор может выдавать до 16 инструкций предварительной выборки перед чтением данных из очереди предварительной выборки по 1 слову за раз.
Обмен сообщениями (Messaging)
Схема поддержки также управляет средством обмена сообщениями. Средство обмена сообщениями передает специальный пакет, называемый сообщением, от одного PE к другому PE. После получения сообщения схема поддержки в PE прерывает работу микропроцессора и помещает сообщение в очередь сообщений. Затем микропроцессор может прочитать сообщение из очереди сообщений.
Очередь сообщений находится в зарезервированной части локальной памяти. Очередь сообщений хранит до 4080 пакетов сообщений и включает 16 зарезервированных ячеек для небольшого переполнения (всего 256 Кбайт информации). Схема поддержки помещает пакеты сообщений в очередь сообщений в порядке их получения.
Чтобы создать сообщение, микропроцессор заполняет одну из строк своего внутреннего буфера записи 4 словами данных. Затем микропроцессор передает данные из буфера записи в схему поддержки. Во время передачи микропроцессор также предоставляет схеме поддержки адрес и информацию о запросе цикла.
После получения адреса и информации запроса цикла от микропроцессора, схема поддержки извлекает код функции и номер PE из записи в приложении DTB. Код функции указывает, что схема поддержки должна выполнить запись сообщения. Затем схема поддержки создает пакет сообщения и отправляет его в PE назначения.
После получения пакета сообщения схема поддержки в PE назначения пытается сохранить сообщение в очереди сообщений. Если очередь сообщений может принять сообщение, схема поддержки сохраняет сообщение в очереди и устанавливает аппаратное прерывание сообщения для микропроцессора. Схема поддержки в PE назначения затем создает пакет подтверждения сообщения и отправляет пакет PE, который создал сообщение.
Если очередь сообщений в PE назначения не может принять сообщение (полная очередь сообщений), схема поддержки возвращает сообщение запрашивающему PE, создавая пакет без подтверждения (NACK). После получения NACK запрашивающий PE может повторно отправить сообщение. Благодаря этой функции доставка сообщений гарантируется независимо от объема системного трафика сообщений.
Помимо пакетов сообщений, схема поддержки может получать «сообщения» об ошибках и сохранять сообщения об ошибках в очереди сообщений. Сетевой интерфейс генерирует сообщения об ошибках, если он получает неправильно направленный пакет или если он получает пакет, содержащий ошибки четности. Если происходит сетевая ошибка, сетевой интерфейс превращает полученный пакет в сообщение об ошибке и отправляет сообщение об ошибке соответствующему PE на узле.
Барьерная синхронизация (Barrier Synchronization)
Схема поддержки также управляет операциями синхронизации барьеров. Есть два типа операций синхронизации барьеров: барьеры и эврики.
Барьер - это точка в программных инструкциях, где микропроцессор должен ждать, пока все другие микропроцессоры, связанные с барьером, завершат свою часть программных инструкций. Программист может использовать барьер, чтобы гарантировать, что все микропроцессоры, связанные с распределенным параллельным циклом в программе, завершат выполнение инструкций цикла перед тем, как продолжить выполнение других программных инструкций.
Схема поддержки в каждом PE содержит два 8-битных регистра, называемых барьерным регистром 0 и барьерным регистром 1. Каждый бит в барьерных регистрах подключен к отдельной схеме синхронизации барьера. Например, на рисунке 13 показана схема синхронизации барьера для бита 2 барьерного регистра 0 в упрощенной системе CRAY T3D.
Все схемы барьерной синхронизации работают одинаково и независимо. В следующих параграфах описывается работа схемы синхронизации барьера, подключенной к биту 2 барьерного регистра 0. Перед началом процесса барьерной синхронизации бит 2 барьерного регистра 0 в каждом PE сбрасывается в логический 0.
Каждая схема синхронизации барьеров в системе CRAY T3D на самом деле представляет собой схему И-дерева и схемы разветвления (снова см. Рисунок 13). Схема И-дерева получает входные данные от всех PE. Схема разветвления дерева отправляет копию последнего выхода логического элемента И всем PE.
Первый слой дерева И содержит четыре логических элемента И. Каждый логический элемент И принимает сигналы от двух PE. Например, один логический элемент И принимает сигналы от бита 2 барьерного регистра 0 в PE 0 и бита 2 барьерного регистра 0 в PE 1. Когда все микропроцессоры устанавливают бит 2 барьерного регистра 0 в 1, выход каждого из четыре И ворота равны 1.
Второй слой дерева И содержит два логических элемента И. Каждый вентиль И принимает сигналы от двух вентилей И в первом слое дерева И. Когда выход всех вентилей И в первом слое дерева И равен 1, выход обоих вентилей И во втором слое дерева И равен 1.
Третий слой дерева И содержит последний элемент И. Этот вентиль И получает сигналы от обоих вентилей И во втором слое дерева И. Когда выход обоих элементов И во втором слое дерева И равен 1, выход последнего элемента И равен 1. Выход последнего элемента И подключается к схеме разветвленного дерева.
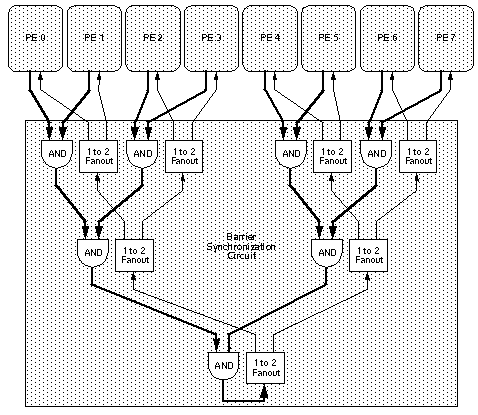

Рисунок 13. Упрощенная схема синхронизации с барьером
.
Первый блок разветвления в дереве разветвления получает 1 от последнего логического элемента И. После создания двух копий 1, первый блок разветвления отправляет единицы двум блокам разветвления во втором слое дерева разветвления.
Каждый из двух блоков разветвления во втором слое дерева разветвления создает по две копии 1. Два блока разветвления во втором слое дерева разветвления отправляют единицы в четыре блока разветвления. в третьем слое разветвленного дерева.
Каждый из четырех блоков разветвления в третьем слое дерева разветвления создает по две копии 1. Блоки разветвления в третьем слое дерева разветвления отправляют единицы в схему поддержки в каждом из восемь PE.
Микропроцессор контролирует схему синхронизации барьера, используя один из двух методов. В первом методе после того, как микропроцессор устанавливает бит 2 барьерного регистра 0 в 1, микропроцессор входит в цикл, который непрерывно проверяет значение бита 2 барьерного регистра 0. После получения 1 от схемы разветвления цепи поддержки сбрасывает бит 2 барьерного регистра 0 в 0. Поскольку микропроцессор постоянно проверяет значение бита 2 барьерного регистра 0, микропроцессор продолжает выполнение программных инструкций, как только бит 2 барьерного регистра 0 сбрасывается в 0.
Во втором методе, после того как микропроцессор устанавливает бит 2 барьерного регистра 0 в 1, микропроцессор разрешает аппаратное прерывание. Затем микропроцессор может выдавать программные инструкции, не связанные с барьером. После получения 1 от схемы разветвления схема поддержки сбрасывает бит 2 барьерного регистра 0 на 0 и устанавливает аппаратное прерывание. Это прерывание указывает микропроцессору, что все микропроцессоры достигли барьера.
Каждая из схем барьерной синхронизации также может использоваться для синхронизации эврики. Синхронизация Eureka использует точку в программных инструкциях, где микропроцессор информируется, когда первый микропроцессор, связанный с eureka, завершил свою часть программных инструкций. Синхронизация Eureka работает как глобальная логическая операция ИЛИ.
Синхронизация Eureka имеет несколько применений, включая поиск в базе данных. Используя синхронизацию эврики, программист может остановить поиск в базе данных, как только какой-либо микропроцессор найдет данные, вместо того, чтобы ждать, пока все микропроцессоры завершат поиск.
При использовании для синхронизации эврики схема синхронизации с барьером работает иначе, чем при использовании для синхронизации с барьером. Перед началом синхронизации эврики каждый микропроцессор, связанный с эврикой, устанавливает соответствующий бит одного из барьерных регистров на 1. Например, каждый микропроцессор может установить бит 2 барьерного регистра 0 в 1.
Как только бит 2 барьерного регистра 0 в каждом PE устанавливается в 1, начинается синхронизация эврики (это событие обычно контролируется отдельной операцией синхронизации барьера). Когда микропроцессор завершает выполнение программных инструкций, связанных с эврикой, микропроцессор сбрасывает бит 2 барьерного регистра 0 в 0. Поскольку все входы в схему синхронизации барьера не равны 1, выход последнего логического элемента И сбрасывается в 0.
Когда выход последнего логического элемента И равен 0, схема разветвления отправляет 0 на схему поддержки в каждом PE. Затем схема поддержки сбрасывает бит 2 барьерного регистра 0 и, если он включен, устанавливает аппаратное прерывание микропроцессора. Это сигнализирует микропроцессору о завершении синхронизации эврики.
Каждая схема синхронизации барьера получает входные данные от всех PE в системе CRAY T3D; однако не все PE в системе должны участвовать в одной и той же операции барьера или эврики. Программное обеспечение поддержки, работающее в хост-системе, может разделить схему синхронизации барьера на более мелкие схемы, каждая из которых принимает входные данные от ограниченного числа PE. Это сделано для того, чтобы более мелкие барьерные схемы синхронизации более точно соответствовали пользовательским разделам.
Каждый вентиль И в дереве И соединяется с блоком разветвления в дереве разветвления. Пара логического элемента И и блока разветвления называется точкой обхода (снова см. Рисунок 13). Программное обеспечение поддержки может перенаправить выход логического элемента И в точке байпаса, чтобы выход логического элемента И подключался к блоку разветвления в точке байпаса. Например, на рисунке 14 показана точка обхода, когда выход логического элемента И не перенаправлен на блок разветвления и когда выход логического элемента И перенаправлен на блок разветвления.

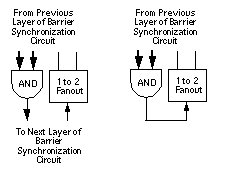
Рисунок 14. Точки обхода
Путем перенаправления вывода логических элементов И в точки обхода различных уровней программное обеспечение поддержки может разделить схему синхронизации физического барьера на комбинацию разделов барьера. Поскольку количество и форма PE в барьерном разделе может не точно соответствовать количеству и форме PE в пользовательском разделе, схема барьерной синхронизации может быть дополнительно разделена программным обеспечением с использованием регистра маски барьера.
Используя регистр барьерной маски и точки обхода, программное обеспечение поддержки может сопоставить барьерный раздел с пользовательским разделом узла PE, чтобы все PE в пользовательском разделе использовали одну и ту же схему синхронизации барьера. Для получения дополнительной информации о пользовательских разделах снова обратитесь к разделу «Номер виртуального PE» в начале этого раздела.
Получение и приращение (Fetch and Increment)
Схема поддержки также выполняет операции чтения или записи в регистры выборки и увеличения. Регистр выборки и увеличения - это специальный регистр, в котором после считывания информации из регистра выборки и увеличения оборудование в узле PE автоматически увеличивает содержимое регистра на единицу (см. Рисунок 15).

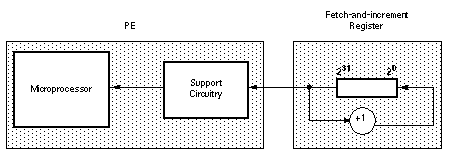
Рисунок 15. Выборка и инкремент.
Каждый узел элемента обработки содержит два регистра выборки и увеличения, каждый из которых имеет размер 32 бита. Этот размер достаточно велик, чтобы содержать значение индекса цикла или значение смещения адреса.
Хотя каждый узел элемента обработки содержит два регистра выборки и увеличения, эти регистры функционируют независимо от PE. Любой PE может использовать любой из регистров выборки и увеличения в разделе.
Регистр выборки и увеличения может использоваться для динамического распределения независимых итераций программного цикла более чем на один микропроцессор. Например, четыре независимых итерации программного цикла могут быть распределены между четырьмя разными микропроцессорами.
Положение дел
Каждый PE содержит регистры, которые показывают состояние операций PE. Информация о состоянии включает в себя информацию об ошибках и невыполненных запросах. Информация о состоянии используется операционной системой.
BLT
The block transfer engine (BLT) is an asynchronous direct memory access device that redistributes system data. The BLT redistributes system data between globally addressable system memory and local memory in either of the PEs in a processing element node. The BLT can create up to 65,536 packets that contain one 64-bit word of data or up to 65,536 packets that contain four 64-bit words of data without interruption from the PE.
Механизм передачи блоков (BLT) - это асинхронное устройство прямого доступа к памяти, которое перераспределяет системные данные. BLT перераспределяет системные данные между глобально адресуемой системной памятью и локальной памятью в любом из PE в узле элемента обработки. BLT может создать до 65 536 пакетов, содержащих одно 64-битное слово данных, или до 65 536 пакетов, содержащих четыре 64-битных слова данных, без прерывания со стороны PE.
BLT выполняет четыре типа операций передачи данных: чтение с постоянным шагом, запись с постоянным шагом, сбор и разброс. Операция чтения с постоянным шагом передает данные из ячеек адреса с фиксированным приращением в системной памяти в ячейки с фиксированным адресом приращения в локальной памяти. Операция записи с постоянным шагом передает данные из ячеек адреса с фиксированным приращением в локальной памяти в ячейки с фиксированным адресом приращения в системной памяти.
Операция сбора передает данные из непоследовательных ячеек памяти в системной памяти в ячейки с фиксированным приращением адреса в локальной памяти. Операция разброса передает данные из ячеек адреса с фиксированным приращением в локальной памяти в ячейки с непоследовательными адресами в системной памяти.
BLT принимает начальные параметры передачи от одного из PE в узле обрабатывающего элемента и затем функционирует независимо от PE. BLT содержит три основных компонента: системную адресацию, локальную адресацию и управление.
Часть системной адресации BLT генерирует адреса, которые используются для ссылки на место в системной памяти (которая включает в себя локальную или удаленную память). Например, схема системной адресации может генерировать адреса, которые указывают на слово считанных данных в удаленном PE во время операции чтения или сбора постоянного шага BLT.
Часть локальной адресации BLT генерирует адреса, которые используются для ссылки на местоположение в локальном PE. Например, схема локальной адресации может генерировать адреса, которые указывают на место в локальной памяти, где будут храниться данные из пакета ответа чтения BLT.
Управляющая часть BLT управляет передачей BLT. Кроме того, схема управления обеспечивает прерывание PE при возникновении ошибки, когда BLT может начать передачу и когда передача BLT завершена
.
Сетевой интерфейс
Сетевой интерфейс собирает исходящие пакеты запроса и ответа и направляет входящие пакеты запроса и ответа на правильный PE в узле. Сетевой интерфейс также содержит регистры выборки и увеличения и управление точкой обхода барьерной синхронизации.
При сборке исходящего пакета запроса или ответа сетевой интерфейс принимает информацию заголовка пакета от PE 0, PE 1 или BLT. Кроме того, сетевой интерфейс может получать данные от PE и получать виртуальный или логический номер PE от PE или BLT.
Если номер PE является виртуальным номером PE, сетевой интерфейс преобразует номер виртуального PE в логический номер PE. Затем сетевой интерфейс преобразует логический номер PE в тег маршрутизации, который используется в исходящем пакете.
При получении входящего пакета сетевой интерфейс проверяет номер узла назначения в заголовке пакета. Если номер узла назначения совпадает с номером узла, в котором находится сетевой интерфейс, пакет прибыл на правильный узел. Затем сетевой интерфейс отправляет пакет в PE назначения. Если номер узла назначения неверен, сетевой интерфейс преобразует пакет в сообщение об ошибке и отправляет сообщение об ошибке одному из PE в узле.
