
7. Классификация аппаратных средств вычислительных систем по Ф.Г. Энслоу.[6]
В основу классификации многопроцессорных вычислительных систем (МВС), предложенной Ф.Г. Энслоу [1], положены разновидности топологии соединительной сети и методы ее работы, определяющие метод соединения аппаратных модулей в единую многопроцессорную вычислительную систему. Эта классификация учитывает степень параллельности потоков информации степень и возможность одновременной работы модулей МВС. Предполагается, что МВС сосредоточена в одном месте таким образом, что расстояния между отдельными ее модулями позволяют передавать информацию со скоростью, согласующейся с производительностью процессоров и пропускной способностью остальных элементов.
Согласно классификации Ф.Г. Энслоу существует несколько типов структурной организации МПВК:
- с общей шиной;
- с перекрестной коммутацией;
- с многовходовыми ОЗУ;
- ассоциативные;
- матричные и векторные,
- конвейерной обработкой.
В комплексах с общей шиной проблема связей всех устройств между собой решается крайне просто: все они соединяются общей шиной, выполненной в виде совокупности проводов или кабелей, по которым передаются информация, адреса и сигналы управления (рис. 7 а). Интерфейс является односвязным, т.е. обмен информацией в любой момент времени может происходить только между двумя устройствами. Если потребность в обмене существует более чем у двух устройств, то возникает конфликтная ситуация, которая разрешается с помощью системы приоритетов и организации очередей в соответствии с этим. Обычно функции арбитра выполняет либо процессор, либо специальное устройство, которое регистрирует все обращения к общей шине и распределяет шину во времени между всеми устройствами комплекса.

Несомненные достоинства структуры с общей шиной - простота, в том числе изменения комплекса, добавления или изъятия отдельных устройств, а также доступность модулей ОЗУ для всех остальных устройств. Следствием всего этого является достаточно низкая стоимость комплекса.
Вместе с тем комплексы с общей шиной не лишены определенных недостатков. Первый - невысокое быстродействие, так как одновременный обмен информацией возможен между двумя устройствами, не более. По этой причине в комплексах с общей шиной число процессоров не превосходит двух-четырех. Этот недостаток может быть несколько компенсирован путем использования общей шины с высоким быстродействием, большим, чем быстродействие входящих в комплекс устройств. Однако этот путь приводит к усложнению и удорожанию комплекса. Второй недостаток МПВК с общей шиной заключается в относительно низкой надежности системы из-за наличия общего элемента - шины. Надо иметь в виду, что надежность общей шины определяется не только надежностью проводов и кабелей (их собственная надежность достаточно высока), но и надежностью всех соединений, входных и выходных цепей устройства. Отказ хотя бы одного из элементов приводит к отказу всего комплекса. Этот недостаток можно компенсировать за счет введения резервной шины (рис. 7,б). Хотя это несколько усложняет комплекс, однако надежность его существенно возрастает. Если же резервную шину сделать активной, т. е. работающей одновременно с основной, то можно не только повысить надежность, но и увеличить производительность комплекса за счет того, что обмен информацией может осуществляться одновременно между двумя парами устройств.
Общая шина может быть организована различными способами - принципиально так же, как и для однопроцессорных ЭВМ с общей шиной. Характерным примером является комплекс СМ-1420, в котором используется общая шина однопроцессорных ЭВМ этой системы.
7.2. С перекрестной коммутацией.
Мультипроцессорные системы, построенные по принципу осуществления связей между модулями посредством "прямоугольной решетки" соединительных шин, которые могут контактировать в любой точке их пересечения, называют системами с перекрестной коммутацией (рис 7.2.1).

Такая организация системы позволяет устанавливать контакт между любыми двумя блоками системы на все время обмена информацией. В отличие от коммутации с временным разделением, реализуемым в системах с общей шиной, рассматриваемый метод переключения связей часто называют коммутацией с пространственным разделением.
Перекрестный коммутатор является "неблокирующимся" в том смысле, что передача через него может быть запрещена из-за отсутствия путей передачи. Существует возможность установить одновременно несколько путей передачи информации в системе. В то же время следует иметь в виду, что коммутатор может быть заблокирован, если одно из соединяемых устройств уже занято.
Одной из ранних структур, в которой реализован принцип перекрестной коммутации, явилась система, получившая название "полиморфная ЭВМ" (рис. 7.2.2). Модули ЭВМ, включающие блоки процессоров и памяти, могли осуществлять связь с периферийными устройствами через центральный коммутатор.
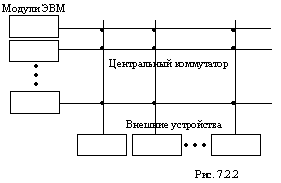
В данной системе была сделана попытка организовать соединения непосредственно между процессорами и перекрестный доступ к памяти путем замыкания соответствующего набора пересечений. Сложность такого способа связи между процессорами и блоками памяти, неэффективность использования оборудования (процессор и память одного единственного модуля, имея единственную шину связи, "мешают" друг другу) выявляют недостатки структуры "полиморфной ЭВМ" по сравнению со структурой системы, приведенной на рис. 7.2.1
Мультипроцессорные системы с перекрестной коммутацией, обладая несколько меньшей гибкостью, чем системы с общей шиной, позволяют тем не менее сравнительно просто вводить новые модули, если коммутационная матрица обладает достаточной емкостью. Матрица полностью отделена от других функциональных блоков и может быть построена также но модульному принципу, что допускает ее расширение. Однако вследствие сложности функций коммутатора, структура его может существенно усложниться.
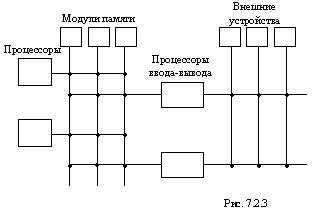
Для обеспечения большей гибкости и увеличения возможностей по расширению в системе может быть введена дополнительная коммутационная матрица устройств ввода-вывода. Такой коммутатор связывается с центральным через процессоры управления вводом-выводом (рис. 7.2.3), при этом устройства ввода- вывода могут подсоединяться к любому каналу. Рассмотренная структура мультипроцессорных систем используется в больших вычислительных системах фирмы "Burroughs" (США).
Оригинальный вариант организации мультипроцессорной конфигурации предложен для системы Multi-Interpreter фирмы "Burroughs", в которую введена группа однотипных процессорных блоков с микропрограммным управлением. Путем перезагрузки блоков микропрограммной памяти одни и те же модули используются в качестве центральных процессоров либо контроллеров ввода - вывода. Благодаря этому все процессоры, модули памяти и периферийные устройства подключены к общей коммутационной матрице (рис. 7.2.4).

Мультипроцессорными системами с перекрестной коммутацией, кроме уже упомянутых зарубежных ЭВМ, являются отечественная вычислительная система высокой производительности "Эльбрус-1" и вычислительный комплекс СМ-2-одна из моделей СМ ЭВМ.
Рассмотрим подробнее структуру вычислительного комплекса СМ-2 (рис. 7.2.5). В этой системе используется модульная структура коммутатора. Восьмиканальный (КМР-8) и четырех- канальный (КМР-4) коммутаторы обеспечивают внутрисистемные связи между устройствами данного ВК. На их основе строится общий распределенный коммутатор, с помощью которого реализуется полная матричная коммутация каждого процессора и канала прямого доступа в память (КПДП) с каждым устройством оперативной памяти (УОП) и согласователем ввода-вывода (СВВ), выполняющим роль контроллера.
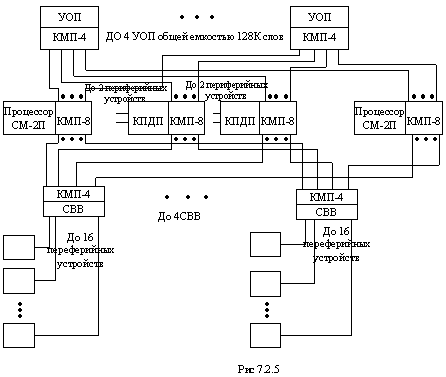
Канал прямого доступа в память является устройством, обеспечивающим быстрый обмен информацией между УОП и периферийными устройствами. Он выполняет операции ввода-вывода независимо от процессора. Взаимное влияние этих устройств проявляется только при попытке одновременного обращения к одному и тому же модулю памяти. При этом приоритет предоставляется каналу, а работа процессора задерживается на время одного цикла обращения к памяти. Обмен информацией с устройствами, подключенными непосредственно через КПДП, может осуществляться со скоростью до 1100000 байт/с. Канал может одновременно обслуживать одно устройство, подключенное непосредственно через КПДП, пли не более четырех устройств ввода-вывода, подключенных через СВВ. В последнем случае скорость обмена меньше л составляет до 550 000 байт/с.
Согласователь ввода-вывода имеет 16 выходов на интерфейс позволяет через один блок подключать до 16 периферийных устройств. С помощью КМР-4 СВВ подключается к процессорам и КПДП.
Рассмотрение структуры вычислительного комплекса СМ-2 позволяет еще раз отметить основные достоинства мультипроцессорных систем с перекрестной коммутацией, в которых обмен информацией возможен одновременно по нескольким путям передачи данных. При этом эффективная скорость передачи может быть выше, чем, например, в системе с временным разделением общей шины, так как контакт устанавливается между взаимодействующими модулями на все время обмена информацией. Благодаря такой системе организации связей не возникают проблем при параллельной работе процессоров. В мультипроцессорной системе с перекрестной коммутацией упрощаются интерфейсы отдельных блоков, поскольку адресация данных и разрешение конфликтов, возникающих при обращении к одному модулю от нескольких источников, осуществляется логикой коммутационной матрицы.
Возникновение конфликтов в коммутационной матрице является в то же время основной причиной снижения эффективности мультипроцессоров с перекрестной коммутацией. Задержки доступа к памяти, вызванные тем, что она используется другими процессорами или устройствами ввода-вывода, снижают быстродействие процессоров и, следовательно, системы в целом.
Полностью лишены недостатков, присущих МПВК с общей шиной, МПВК с перекрестной коммутацией. Идея структурной организации таких ВК заключается в том, что все связи между устройствами осуществляются с помощью специального устройства - коммутационной матрицы. Коммутационная матрица (КМ) позволяет связывать друг с другом любую пару устройств, причем таких пар может быть сколько угодно: связи не зависят друг от друга.
В МПВК с перекрестной коммутацией нет конфликтов из-за связей, остаются только конфликты из-за ресурсов. Возможность одновременной связи нескольких пар устройств позволяет добиваться очень высокой производительности комплекса. Важно отметить и такое обстоятельство, как возможность установления связи между устройствами на любое, даже на длительное время, так как это совершенно не мешает работе других устройств, зато позволяет передавать любые массивы информации с высокой скоростью, что также способствует повышению производительности комплекса. Заметим, что в МПВК с общей шиной передача информации массивами, т.е, занятие шины одной парой устройств на длительный отрезок времени, обычно допускается лишь в крайних случаях, так как это приводит к длительным простоям остальных устройств.
Кроме того, к достоинствам структуры с перекрестной коммутацией можно отнести простоту и унифицированность интерфейсов всех устройств, а также возможность разрешения всех конфликтов в коммутационной матрице. Важно отметить и то, что нарушение какой-то связи приводит не к выходу из строя всего комплекса, а лишь к отключению какого-либо устройства, т.е. надежность таких комплексов достаточно высока. Однако и организация МПВК с перекрестной коммутацией не свободна от недостатков.
Прежде всего - сложность наращивания ВК. Если в коммутационной матрице заранее не предусмотреть большого числа входов, то введение дополнительных устройств в комплекс потребует установки новой коммутационной матрицы. Существенным недостатком является и то, что коммутационная матрица при большом числе устройств в комплексе становится сложной, громоздкой и достаточно дорогостоящей. (Надо учитывать то обстоятельство, что коммутационные матрицы строятся обычно на схемах, быстродействие которых существенно выше быстродействия схем и элементов основных устройств, - только при этом условии реализуются все преимущества коммутационной матрицы.) Это обстоятельство в значительной степени усложняет и удорожает комплексы.
Для того чтобы упростить и удешевить ВК, коммутацию устройств осуществляют с помощью двух и даже более коммутационных матриц. Перекрестная коммутация довольно широко используется при построении ВК, в частности практически всех МПВК фирмы "Барроуз" (в том числе и упомянутого выше комплекса D-825).
В МПВК с многовходовыми ОЗУ все, что связано с коммутацией устройств, осуществляется в ОЗУ. В этом случае модули ОЗУ имеют число входов, равное числу устройств, которые к ним подключаются, т. е. для каждого устройства предусматривается свой вход в ОЗУ. В отличие от ВК с перекрестной коммутацией, которые -имеют централизованное коммутационное устройство, в МПВК с многовходовыми ОЗУ средства коммутации распределены между несколькими устройствами. Такой способ организации МПВК сохраняет все преимущества систем с перекрестной коммутацией, несколько упрощая при этом саму систему коммутации. Для наращивания системы должны быть предусмотрены дополнительные входы в ОЗУ. Правда, введение дополнительных модулей ОЗУ не вызывает затруднений.
7.3 МПВК с многовходовыми ОЗУ.
Как и системы, описанные в предыдущем параграфе, мультипроцессоры с многовходовой памятью используют несколько путей одновременной передачи информации (рис. 7.3.1). Такая топология схемы соединений более экономична, чем конфигурация с перекрестным коммутатором, так как в ней, вообще говоря, меньше точек, в которых могут возникать конфликты, требующие разрешения. Модули памяти в мультипроцессорах данного типа должны иметь по нескольку входов.

Кроме того, блоки памяти должны быть снабжены логическими схемами, предназначенными для разрешения конфликтов, в тех случаях, когда несколько процессоров или внешних устройств требуют одновременного доступа к одному и тому же модуле оперативной памяти. Таким образом, в системах с многовходовой памятью каждый модуль памяти должен идентифицировать и обрабатывать запросы на доступ к определенным ячейкам памяти. Устройство управления памятью при этом разрешает конфликты при одновременном обращении и сообщает обратившемуся к модулю памяти устройству системы, что ему разрешен доступ к данному модулю.
Максимально возможная конфигурация в мультипроцессорax рассматриваемого типа ограничена числом входов модулей памяти Наращивание дан. ной конфигурации возможно путем использования мультиплексоров на входе модулей оперативной памяти, однако скорость передачи данных в такой системе не выше скорости передачи при отсутствии мультиплексоров.
Необходимо отметить, что входы модуля памяти в системах рассматриваемого типа могут обладать разными приоритетами, обусловленными различием точек физических (электрических) соединений. Эта особенность может быть использована для разрешения конфликтов при одновременных запросах. Приоритет в таком случае отдается процессору или внешнему устройству, обращающемуся к "своему" модулю памяти (рис. 7.3.2).

Существуют конфигурации мультипроцессорных систем с многовходовой памятью, в которых каждый процессор имеет "собственную" память (рис. 7.3.3). В собственной памяти могут храниться, например, специальные таблицы операционной системы, необходимые при реализации функций управления, распределения ресурсов, восстановления и т. п. Однако если каждый процессор не имеет доступа к любому модулю памяти, универсальность мультипроцессорной системы утрачивается. При этом существенно уменьшается гибкость функционирования операционной системы и перемещения в памяти объектных программ.
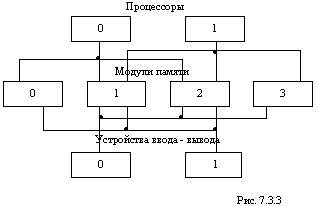
Если, например, какой-либо процессор вышел из строя и прерванную работу необходимо закончить с помощью другого процессора, то может оказаться, что новому процессору будет недоступна информация, необходимая для выполнения этой задачи. Аналогичные трудности может вызвать также выход из строя модуля собственной памяти некоторого процессора. Таким образом, конфигурацию с собственной памятью отличает более низкая надежность системы.
В системах с многовходовой памятью, как и в мультипроцессорах с коммутатором, ширина пути передачи данных определяется экономичностью и производительностью. Если основной единицей хранения данных является слово, а ширина пути передачи информации меньше слова, то интерфейс должен содержать специальную аппаратуру для упаковки и распаковки слов. Эта аппаратура должна также следить за тем. чтобы путь передачи не был разорван, пока передача слова не будет закончена, и чтобы а него не была введена другая информация.
Типичными мультипроцессорными системами с многовходовой памятью являются системы UNIVAC-1108, UNIVAC-1832, IBM-S/360 (модель 67), IBM-S/370 (модели 158 и 168) и др. В МПВК с многовходовыми ОЗУ очень просто решается вопрос о выделении каждому процессору своей оперативной памяти, недоступной другим процессорам. Выделение индивидуальной памяти каждому процессору позволяет хранить в ней информацию, которая необходима только одному процессору: различные таблицы и данные, копии некоторых модулей операционной системы и др. Это позволяет избежать части конфликтов, которые неизбежно возникают при Общей Оперативной памяти. Кроме того, уменьшается вероятность искажения Информации в ОЗУ другими процессорами. Однако такие ВК имеют тот недостаток, что в случае выхода из строя какого, либо процессора доступ к его памяти затруднен и информация может быть переписана в другой модуль ОЗУ через канал ввода - вывода и внешнее ЗУ, что требует времени.
Исследования производителей вычислительной техники показали, что системы обработки информации, поступающей от многих датчиков, системы слежения за многими движущимися объектами и другие специализированные системы обработки наиболее эффективно могут быть реализованы на структурах аппаратных средств, обладающих свойствами ассоциативности и параллельности.
Понятие "ассоциативная система" означает, что обработка данных в системе может производиться не только обычными средствами адресации, указывающими на местоположение единиц информации в памяти, но и путем идентификации и выбора данных по их содержанию. Структура такой вычислительной системы основывается на использовании ассоциативной памяти, дополнительная логика которой обеспечивает адресацию слов по содержанию.
Принцип ассоциативного обращения к информации может быть использован при приеме и размещении в памяти входных потоков данных с целью последующего выбора всех слов с заданными свойствами для выходных потоков. На базе ассоциативной памяти реализуются также функции, связанные с перестроением данных, т.е. изменением места и порядка расположения элементов информации.
Итак, высокая степень параллельности обработки может быть достигнута тогда, когда одноименные операции выполняются одновременно над всем множеством содержащихся в выделенном поле ассоциативной памяти слов. Для этого в состав ассоциативной вычислительной системы вводятся обрабатывающие элементы, реализующие арифметическую и логическую обработку информации. Упрощенная структура связки ассоциативная память - обрабатывающие элементы (ОЭ) представлена на рис.7.4.1.

Достижение наивысшей степени параллельности обработки возможно, когда число ОЭ соответствует числу обрабатываемых слов. При этом, если они (слова) обрабатываются последовательно поразрядно, то в текущий момент времени элементы (ОЭ) обрабатывают разрядный срез всех слов данных.
Рассмотрим организацию ассоциативного матричного модуля (рис. 7.4.2). Его основу составляет память с многоразмерным доступом - матрица 256х256 элементов (разрядов), которая позволяет считывать и записывать информацию по разрядным срезам (в горизонтальном направлении) и по словам (в вертикальном направлении). Первый метод обращения используется при выполнении операций над разрядными срезами, а второй - при вводе - выводе для организации параллельного доступа ко всем разрядам слов.
Три 256-разрядных регистра M, X, Y составляют модуль обрабатывающих элементов. В состав каждого элементарного процессора входит по одному разряду из названных регистров. Регистр маски (М) позволяет маскировать элементы 256-разрядных кодов. Регистры X, Y и связанная с ними логика предназначены для выполнения логических операций над двумя переменными.
Мультиплексор обеспечивает поочередное использование перестановочной сети различными устройствами модуля: памятью, регистрами, магистралями- ввода-вывода. Перестановочная сеть играет важную роль при реализации операций перестроения данных в ассоциативной памяти. Она осуществляет взаимное соединение ОЭ для передачи информации из одного элемента в другой. Это достигается управляемой перестановкой разрядов (одиночных или группами) при передаче слов через сеть. Многократной передачей данных через перестановочную сеть можно добиться сложных их перестроений как в вертикальном, так и в горизонтальном направлении.
Описание работы элементарных процессоров ассоциативного матричного модуля можно выполнить, введя следующую систему обозначений.

Пусть ![]() -состояние i-го регистра
-состояние i-го регистра ![]() состояние того же регистра
состояние того же регистра ![]() состояние i-го выхода перестановочной сети, F-логическая функция двух переменных. Рассмотрим три варианта операций, реализуемых обрабатывающими элементами:
состояние i-го выхода перестановочной сети, F-логическая функция двух переменных. Рассмотрим три варианта операций, реализуемых обрабатывающими элементами:
1. совместную независимую реализацию одинаковых логических функций:
![]()
2. селективную реализацию указанных функций:
![]() при
при ![]() при
при ![]()
3. селективную и независимую их реализацию:
![]() при
при![]() при
при ![]()
В последнем случае для маскирования операций на регистре Х используется состояние регистра Y, в котором он находится перед модификацией посредством F.
Наиболее характерным представителем группы ассоциативных вычислительных систем является система STARAN, разработанная в США. От матричных систем, описанных ниже, она отличается не только наличием ассоциативной памяти, но и другими особенностями: ассоциативная память является памятью с многомерным доступом, т. е. в нее можно обратиться как поразрядно, так и пословно; операционные процессорные элементы предусмотрены для каждого слова памяти; имеется уникальная схема перестановок для перегруппировки данных в памяти. Основным элементом системы является многомерная ассоциативная матрица - ассоциативный модуль (АМ), который представляет собой квадрат из 256 разрядов из 256 слов, т.е, содержит в общей сложности 65536 бит данных. Для обработки информации имеется 256 процессорных элементов, которые последовательно, разряд за разрядом, обрабатывают слова. Все ПЭ работают одновременно, по одной команде, выдаваемой устройством управления. Таким образом, сразу по одной команде обрабатываются все выбранные по определенным признакам из памяти слова.
Схема перестановок позволяет сдвигать и перегруппировывать данные так, чтобы над словами, хранящимися в памяти, можно было выполнять параллельно арифметические и логические операции. Большая часть операций выполняется в отношении каждого из 256-разрядных слов. Операции, в которых участвуют несколько слов, используются достаточно редко. Обычно 256-разрядное слово ассоциативной матрицы разбивается программистом на поля переменной длины, и в процессе обработки именно над этими полями производятся арифметические и логические действия.
Базовая конфигурация системы содержит один АМ. Однако число этих модулей может варьироваться в системе от 1 до 32. Таким образом, при максимальной комплектации в системе может подвергаться ассоциативной обработке 256 кбайт информации. Скорость поиска и обработки информации 256 процессорными элементами высока, и остальные элементы системы спроектированы так, чтобы поддерживать эту скорость.
Если не считать машины Унгера (1958г.), которая была узкоспециализированной и предназначалась только для решения задач распознавания образов, то, по-видимому, первой матричной системой следует считать систему SOLOMON. Система содержит 1024 ПЭ, соединенных в виде матрицы 32Х32. Каждый ПЭ в матрице соединен с четырьмя соседними и включает в себя процессор, обеспечивающий выполнение последовательных поразрядных арифметических и логических операций, а также оперативное ЗУ емкостью 16 кбит, разбитое на модули по 4 кбит каждый. Длина слова переменная - от 1 до 128 разрядов. Разрядность слов устанавливается программно. По каналам связи от УУ передаются команды и общие константы. В ПЭ используется так называемая многомодальная логика, которая позволяет каждому ПЭ выполнять (т.е. быть активным) или не выполнять (быть пассивным) общую операцию в зависимости от значений обрабатываемых данных.
В каждый момент все активные ПЭ выполняют одну и ту же операцию над данными, хранящимися в собственной памяти и имеющими один и тот же адрес. Идея многомодальности заключается в том, что в каждом ПЭ имеется специальный регистр на четыре состояния - регистр моды.

Мода (или модальность) заносится в этот регистр от УУ. При выполнении последовательности команд модальность передается в коде операции и сравнивается с содержимым регистра моды. Если есть совпадение, то операции выполняется. В других случаях ПЭ не выполняет операцию, но может в зависимости от кода пересылать свои операнды соседнему ПЭ. Такой механизм позволяет, в частности, выделить строку или столбец ПЭ, что может быть полезным при операциях над матрицами. Взаимодействуют ПЭ с периферийным оборудованием через внешние ПЭ.
Система SOLOMON оказалась нежизнеспособной вследствие громоздкости, недостаточной гибкости и эффективности. Однако идеи, заложенные в ней, получили развитие в системе ILLIAC-IV, разработанной Иллинойским университетом и изготовленной фирмой "Барроуз".
В каждом квадранте 64 ПЭ образуют матрицу размером 8Х8. Схема связей между ПЭ похожа на схему системы SOLOMON, но связь с внешней средой имеют все ПЭ без исключения. Реально действующая система ILLIAC-IV состоит, таким образом, из двух частей; центральной с устройством управления и 64 ПЭ, а также подсистемы ввода - вывода, включающей в себя универсальную ЭВМ В-6700, файловые диски и лазерную архивную память большой емкости. Каждый ПЭ состоит из собственно процессора и ОЗУ. Процессор оперирует с 64-разрядными числами и выполняет универсальный набор операций. Быстродействие процессора достаточно высокое: операция сложения 64-разрядных чисел выполняется за 240 нс, а умножения - за 400 нс. Таким образом, процессор выполняет в среднем 3 млн. операций в секунду, а следовательно производительность системы равна ЗХ64 200 млн. операций в секунду.
Емкость ОЗУ каждого ПЭ составляет 2048 64-разридных слов, длительность цикла обращения к памяти 350 нс. Память выполнена на интегральных схемах. Каждый процессор имеет счетчик адресов и индексный регистр, так что конечный адрес в каждом процессоре может формироваться как сумма трех составляющих: адреса, содержащегося в команде для данного ПЭ, кода. Это существенно повышает гибкость системы по сравнению с системой SOLOMON, где все ПЭ выбирают информацию по одному адресу. Каждый процессор кроме индексного регистра имеет в своем составе пять программно-адресуемых регистров: накапливающийся сумматор, регистр для операндов, регистр пересылок, используемый при передачах от одного ПЭ к другому, буферный регистр на одно слово и регистр управления состоянием ПЭ (аналогичный регистру моды в системе SOLOMON). Регистр управления имеет 8 разрядов. В зависимости от содержимого этого регистра ПЭ становится активным или пассивным, а также выполняет ряд пересылочных операций. Если вычисления не требуют полной разрядности, то процессор может быть разбит на два 32-разрядных подпроцессора или даже восемь 8-раэрядных. Это позволяет в случае необходимости обрабатывать векторные операнды из 64, 2Х64=128 и 8Х64=512 элементов.
Система ILLIAC была включена в состав вычислительной сети АКРА. В результате усовершенствования программного обеспечения производительность системы выросла до 300 млн. операций в секунду.
7.6. КОНВЕЙЕРНАЯ ОБРАБОТКА ИНФОРМАЦИИ.
Принцип конвейерной обработки информации нашел широкое применение в вычислительной технике. В первую очередь это относится к конвейеру команд. Практически все современные ЭВМ используют этот принцип. Вместе с тем во многих вычислительных системах наряду с конвейером команд используется и конвейер данных. Сочетание этих двух конвейеров дает возможность достигнуть очень высокой производительности систем на определенных классах задач, особенно если при этом используется несколько конвейерных процессоров, способных работать одновременно и независимо друг от друга. Именно так и построены самые высокопроизводительные системы. Целесообразнее всего рассмотреть принцип конвейерной обработки на примере некоторых, наиболее представительных систем.
К числу ЭВМ, в которых широкое применение нашел конвейер команд, относится одна из лучших отечественных машин БЭСМ-6. Эта ЭВМ, разработанная под руководством академика С. А. Лебедева в 1966 г., была в течение многих лет самой быстродействующей в стране благодаря целому ряду интересных решений, в том числе и конвейеру команд. Последний обеспечивался использованием восьми независимых модулей ОЗУ, работающих в системе чередования адресов, и большого числа быстрых регистров, предназначенных также и для буферизации командной информации. Это позволило получить на БЭСМ-6 производительность 1 млн операций в секунду.
- Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 1976. 383с.
- Архитектура многопроцессорных вычислительных систем: Учеб. Пособие / Козлов О.С., Метлицкий Е.А., Экало А.В. и др.; Под ред. В.И Тимохина:- Л.: Изд-во Ленингр. ун-та, 1981.
- Смирнов А.Д. Архитектура вычислительных систем: Учеб. пособие для вузов. М.: Наука. Гл. ред. физ.мат. лит., 1990. 320 с.
