
Принцип векторной обработки. Векторно-конвейерные и матричные вычислительные системы. Факторы снижающие производительность векторных систем.[1]
2.Общие принципы организации высокопроизводительных ЭВМ организации высокопроизводительных ЭВМ и высокоскоростных вычислений
2.1. Повышение быстродействия
2.2. Организация быстродействующих вычислительных систем
3. Принципы векторной обработки
4. Факторы, снижающие пропускную способность
5. Оценка общей производительности
6. Литература
1. ПРЕДИСЛОВИЕ
Появление супер ЭВМ в качестве самостоятельного класса вычислительных машин произошло в начале 80-х гг. К середине 1985 г. в мире действовало более 150 таких ЭВМ стоимостью около 10 млн. долл. каждая.
Важным фактором, послужившим причиной внезапного роста их популярности, является внезапное и очень резкое увеличение производительности ЭВМ за счет внедрения векторной обработки. В 70-х гг. ряд смелых идей был воплощен в целом классе машин, которые не имели коммерческого успеха, зато проложили путь к созданию нынешнего поколения суперЭВМ. Именно тогда впервые были реализованы принципы параллельной и векторной обработки. В 80-х гг. векторные машины практически стали обыденным явлением.
2. ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ЭВМ И ВЫСОКОСКОРОСТНЫХ ВЫЧИСЛЕНИЙ
Повышение производительности вычислительных систем предусматривает прежде всего достижение высокой скорости исполнения программ. Такая цель соответствует как требованиям пользователей, заинтересованных в наиболее быстром получении результатов счета, так и тому обстоятельству, что быстродействие определяет общее количество вычислительной работы, которую способна выполнить система за данный отрезок времени.
В ряде прикладных областей повышение скорости вычислений играет большую роль, так как время решения задач на стандартных ЭВМ обычно оказывается слишком большим с точки зрения практического использования результатов. Разумеется, стоимостные факторы и в этом случае имеют существенное значение, однако более важным становится обеспечение самой возможности получения результатов за приемлемое время при минимальной (насколько это удается) стоимости вычислений.
Именно в таких прикладных областях и требуются суперЭВМ.
Основными факторами, определяющими высокую стоимость суперЭВМ, являются:
1. Большие затраты на конструирование, обусловленные сложностью оборудования и относительно малым серийным выпуском.
2. Высокая стоимость аппаратуры, для создания которой требуются новые технологии, способные обеспечить предельные для нынешнего уровня развития техники показатели. На стоимость аппаратуры влияют также увеличение числа логических элементов, количества выделяемой теплоты в единице объема и другие подобные факторы.
3. Дорогостоящее программное обеспечение, включающее специальные средства, которые позволяют реализовать потенциально высокое быстродействие систем.
Область применения методов достижения высокого быстродействия охватывает все уровни создания систем.
На самом нижнем уровне - это передовая технология конструирования и изготовления быстродействующих элементов и плат с высокой плотностью монтажа. В этой сфере лежит наиболее прямой путь к увеличению скорости, поскольку если бы, например, удалось все задержки в машине сократить в К раз, то это привело бы к увеличению быстродействия в такое же число раз. В последние годы были достигнуты огромные успехи в создании быстродействующей элементной базы и адекватных методов монтажа, и ожидается дальнейший прогресс, основанный на использовании новых технологий и снижения размеров устройств. Этот путь, однако, имеет ряд ограничений:
1. Для определенного уровня технологии обеспечивается определенный уровень быстродействия элементной базы: как только он оказался достигнутым, дальнейшее увеличение быстродействия сопровождается огромными расходами вплоть до достижения того порога, за которым уже нет технологий, обеспечивающих большее быстродействие.
2. Более быстродействующие элементы обычно имеют меньшую плотность монтажа, что, в свою очередь, требуют более длинных соединительных кабелей между платами и, следовательно, приводит к увеличению задержек (за счет соединений) и уменьшению выигрыша в производительности.
3. Более быстродействующие элементы обычно рассеивают больше тепла. Поэтому требуются специальные меры по теплоотводу, что еще больше снижает плотность монтажа и, следовательно, быстродействие. Для того чтобы избежать дополнительных расходов, задержек за счет соединений и увеличения рассеяния тепла, целесообразно, по-видимому, применять быстродействующие элементы не везде, а только в тех частях, которые соответствуют <узким местам>. Например, чтобы увеличить скорость сложения, можно применить высокоскоростные схемы только в цепи переноса. Однако путь увеличения быстродействия элементов имеет свои ограничения и может наступить момент, когда станет необходимым или более целесообразным использовать для реализации операции сложения другие способы.
Следующий шаг в направлении повышения быстродействия предполагает уменьшение числа логических уровней при реализации комбинационных схем. Хорошо известно, что любая функция может быть реализована с помощью схемы с двумя логическими уровнями. Однако в сложных системах это приводит к появлению громоздких устройств, содержащих очень большое число вентилей с чрезмерными коэффициентами соединений по входу и выходу. Следовательно, на данном этапе конструкторская задача состоит в создании схем с малым числом логических уровней, которое бы удовлетворяло ограничениям по количеству вентилей и их коэффициентам соединений по входу и выходу. В настоящее время разработаны принципы построения схем, требующих меньшее число вентилей и обладающих меньшими задержками, и предложены методы их создания. В силу присущих ограничений только один этот путь, как правило, не может дать требуемого увеличения производительности.
Следующий уровень охватывает способы реализации основных операций, таких как сложение, умножение и деление. Для того чтобы увеличить cкорость выполнения этих операций, необходимо использовать алгоритмы, которые приводили бы к быстродействующим комбинационным схемам и требовали небольшого числа циклов. В результате успешных исследований и разработок в области арифметических устройств создан ряд алгоритмов, которые могут быть использованы в условиях тех или иных ограничений. С точки зрения применения высокопроизводительных вычислительных машин для научных расчетов особый интерес представляет реализация принципа опережающего просмотра при операциях сложения, сложения с сохраняемым переносом и записи при матричном умножении. Сюда же относятся проблемы использования избыточности при делении и реализация деления в виде цепочки операций умножения.
Далее, быстродействие вычислительных систем может быть повышено за счет реализации аппаратными или программно-аппаратными средствами встроенных сложных командсоответствующих тем или иным функциям, встречающимся во многих практических вычислениях. К таким функциям относятся, например, корень квадратный, сложение векторов, умножение матриц и быстрое преобразование Фурье. Указанные средства позволяют сократить число команд в программах и создают предпосылки для более эффективного использования машинных ресурсов (например, конвейеризованных арифметических устройств). При решении некоторых задач получаемый выигрыш может быть весьма существенным, что особенно хорошо видно на примере рассматриваемых ниже векторных ЭВМ, в которых основную роль играют векторные команды. С другой стороны, непросто определить такие сложные команды, которые бы достаточно часто использовались в широком классе прикладных программ. В то же время исследования процессов выполнения большого числа программ из разных прикладных областей показывают, что существует явное смещение частот использования в направлении небольшого набора простых команд. Этот факт послужил основой для развития подхода, при котором из множества команд выделяется небольшое подмножество простых и часто используемых команд, подлежащих оптимизации. В настоящее время уже разработан ряд экспериментальных и промышленных образцов процессоров, использующих принцип оптимизации сокращенного набора команд. Влияние этого подхода на прогресс в области высокоскоростных вычислений нуждается в оценке.
Еще один резерв, используемый для повышения эффективности работы процессора,- это сокращение временных затрат при обращениях к памяти. Обычные подходы здесь состоят, во-первых, в расширении путей доступа за счет разбиения памяти на модули, обращение к которым может
осуществляться одновременно; во-вторых, в применении дополнительной сверхбыстродействующей памяти (кэш-памяти) и, наконец, в увеличении числа внутренних регистров в процессоре. Как показано ниже, использование всех перечисленных способов тесно связано с организацией систем. Длительность исполнения одной команды может быть уменьшена за счет временного перекрытия различных ее фаз. К примеру, вычисление адреса, по которому нужно записать результат, может быть выполнено одновременно с самой операцией. Этот подход требует, разумеется, дополнительного оборудования, поскольку модули памяти не могут быть одновременно задействованы в совмещаемых фазах. Увеличение быстродействия, которое можно при этом достичь, зависит от формата (состава) команды, поскольку именно им определяется наличие независимых фаз.
Наконец, мы подходим к структуре алгоритма, по которому работает система. На этом уровне основной подход к повышению быстродействия состоит в том, чтобы выполнять одновременно несколько команд. Этот подход отличается от того, который реализован в обычной фон-неймановской машине, когда команды исполняются строго последовательно одна за другой. Параллельный подход приводит к различным вариантам архитектуры в зависимости от способа, по которому осуществляется задание очередности следования команд и управление их исполнением. Распараллеливание позволяет значительно увеличить производительность систем при решении широкого класса прикладных задач.
Перечисленные подходы касаются аппаратуры, логической организации и архитектуры систем. Усилия, затрачиваемые в этих областях, имеют своей целью обеспечение необходимого ускорения вычислений на программно-алгоритмическом уровне. На этом уровне должны использоваться либо специальные языки программирования, предоставляющие средства для явного описания параллелизма, либо методы выявления параллелизма в последовательных программах. Кроме того, алгоритм должен обладать внутренним параллелизмом, соответствующим особенностям данной архитектуры. Использование неадекватных алгоритмов и языков способно практически свести на нет возможности для реализации высокоскоростных вычислений, заложенные в архитектуре.
2.2. ОРГАНИЗАЦИЯ БЫСТРОДЕЙСТВУЮЩИХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Как отмечалось в предыдущем параграфе, главный организационный принцип, ведущий к повышению быстродействия, подразумевает одновременное выполнение нескольких команд. В этом разделе мы рассмотрим возможные варианты организации систем и покажем, что эффективность их использования связана со структурами вычислительных алгоритмов.
Алгоритм - это описание вычислительного процесса в виде последовательности более простых вычислительных конструкций. Алгоритм включает спецификации этих вычислительных конструкций и отношений следования между ними. Алгоритмические структуры отличаются друг от друга содержанием простых вычислительных конструкций и типом отношения следования.
Вычислительные конструкции, образующие алгоритм, могут быть различными по степени сложности объектами: от простых арифметических операторов до функций. В действительности же концепция алгоритма подразумевает иерархию в том смысле, что вычислительная конструкция в свою очередь может быть описана в виде алгоритма, состоящего из еще более простых вычислительных конструкций. В контексте рассуждений о параллелизме это приводит к понятию детализации параллелизма. Детализацию называют мелкой, если вычислительные конструкции алгоритма являются примитивными (т. е. реализуемыми одной командой), и крупной, если эти конструкции являются сложными (т. е. реализуются с помощью другого алгоритма). Разумеется, спектр значений детализации параллелизма простирается от очень мелкой до очень крупной. Более того, в системах может использоваться комбинированная детализация.
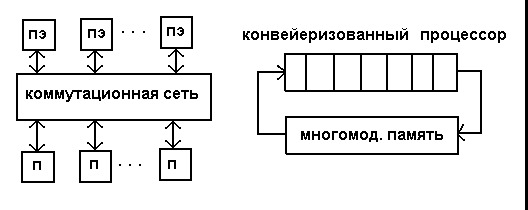
Рис. 2.1. Матричная вычислительная система (левый рисунок)
Рис. 2.2. Конвейерная вычислительная система (правый рисунок)
где (ПЭ - процессорные элементы, П - модули памяти)
Основной тип организации векторной вычислительной системы изображен на рис.2.3. Он включает блок обработки команд, осуществляющий вызов и декодирование команд, векторный процессор, исполняющий векторные команды, скалярный процессор, исполняющий скалярные команды, а также память для хранения программ и данных. Последняя делится на главную память и память второго уровня, что обеспечивает ей необходимую емкость и пропускную способность при приемлемой стоимости. Компоненты векторного процессора, также изображенные на рис. 2.3, рассмотрены ниже.

Рис.2.3. Структура векторной вычислительной системы
Чтобы показать, какой выигрыш в производительности дает векторная машина, рассмотрим операцию сложения двух векторов на рис. 2.4,а изображены скалярная программа и временная диаграмма ее исполнения на обычной ЭВМ, в которой реализован опережающий просмотр в сочетании с конвейерным исполнением операций. На рис. 2.4,б изображены соответствующая векторная программа и временная диаграмма.
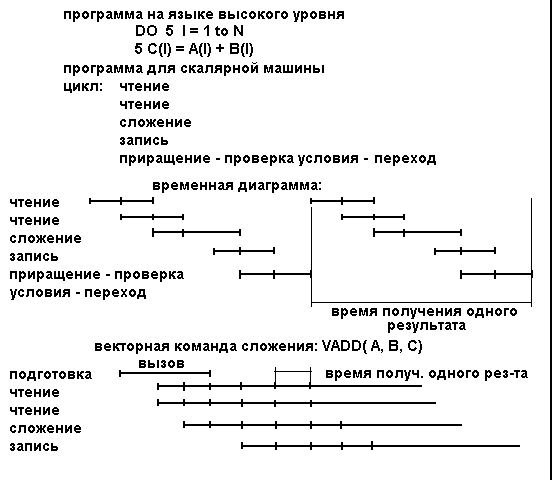
Рис.2.4. Вычисление суммы двух векторов.
а - на скалярном процессоре; б - на векторном процессоре
3. ПРИНЦИПЫ ВЕКТОРНОЙ ОБРАБОТКИ.
Принцип векторной обработки основан на существовании значительного класса задач использующих операции над векторами. Алгоритмы этих задач в соответствии с терминологией Флинна относятся к классу ОКМД (одиночный поток команд, множественный поток данных). Реализация операций обработки векторов на скалярных процессорах с помощью обычных циклов ограничивает скорость вычислений по следующими причинам.
- Перед каждой скалярной операцией необходимо вызывать и декодировать скалярную команду.
- Для каждой команды необходимо вычислять адреса элементов данных
- Данные должны вызываться из памяти, а результаты запоминаться в памяти. В больших ЭВМ память выполняется, как правило, в виде набора модулей, доступ к которым может осуществляться одновременно. В условиях когда каждая команда вырабатывает свой собственный запрос к памяти, такой раздробленный доступ может стать причиной возникновения конфликтов обращения к памяти, препятствующих эффективному использованию ее потенциальной пропускной способности.
- Необходимо осуществлять упорядочение выполнения операций в функциональных устройствах. В целях увеличения производительности эти устройства строятся по конвейерному принципу. Эффективному использованию конвейерных устройств препятствует последовательная “природа” оператора цикла.
- Реализация команд построения циклов (счетчик и переход) сопровождается накладными расходами. Кроме того, наличие в цикле команды перехода препятствует эффективному использованию принципа опережающего просмотра.
Влияние перечисленных отрицательных факторов уменьшается при введении векторных команд, с помощью которых задается одна и та же операция над элементами одного или нескольких векторов, и организации, системы, которая обеспечивает эффективное исполнение таких команд. Этот подход реализуется в системах двух типов: матричных и векторно-конвейерных.
- Матричная система состоит из множества процессорных элементов (ПЭ), организованных таким образом, что они исполняют векторные, команды, задаваемые общим для всех устройством управления, причем каждый ПЭ работает с отдельным элементом вектора. ПЭ соединены через коммутационное устройство с многомодульной памятью. Исполнение векторной команды включает чтение из памяти элементов векторов, распределение их по процессорам, выполнение заданной операции и засылку результатов обратно в память.
- В векторно-конвейерной системе, напротив, имеется один (или небольшое число) конвейерный процессор, выполняющий векторные команды путем засылки элементов векторов в конвейер с интервалом, равным длительности прохождения одной, стадии обработки. При этом скорость вычислений зависит только от длительности стадии и не зависит от задержек в процессоре в целом.
Оба подхода в принципе позволяют достичь значительного ускорения по сравнению со скалярными машинами. Более того, ускорение в системах матричного типа может быть больше, чем в конвейерных, поскольку увеличить число процессорных элементов проще, чем число ступеней в конвейерном устройстве. В настоящее время созданы и успешно применяются системы обоих типов. К наиболее значительным представителям семейства матричных систем относятся одна из первых крупных разработок – ILLIAC IV - системы DAP фирмы ICL, BSP фирмы Burrougs и МРР фирмы Goodyear. Класс конвейерных систем включает такие системы, как STAR100 и Суbег 205 фирмы СDС, Сгау-1 фирмы Сгау >Research, S-810 фирмы НIТАСНI, SХ NЕС и FАСОМ, VР-200 фирмы Fujitsu. Тот факт, что большинство суперЭВМ относится к классу конвейерных систем, свидетельствует, похоже, о том, что для современного уровня технологии такие системы являются более гибкими и эффективными с точки зрения стоимости.
4. ФАКТОРЫ, СНИЖАЮЩИЕ ПРОПУСКНУЮ СПОСОБНОСТЬ
Существует ряд факторов, приводящих к тому, что при выполнении реальных программ производительность векторных ЭВМ оказывается значительно ниже максимально возможной. Мы обсудим наиболее важные из них и покажем, какие показатели могут служить мерой снижения производительности.
4.1. Скалярная обработка
Невозможно построить реальную прикладную программу, состоящую только из векторных операций. Значительная часть вычислений остается скалярной, причем некоторые скалярные команды служат для подготовки, векторных команд и управления их прохождением. Поскольку векторные устройства не обеспечивают эффективного исполнения этих команд, в состав оборудования входит скалярный процессор. Всякий раз, когда исполнение какой-либо скалярной операции не полностью перекрывается по времени векторными вычислениями, происходит снижение производительности.
Величина снижения может быть получена исходя из доли скалярных операций (f)и отношения максимальной пропускной способности в векторном режиме к пропускной способности в скалярном режиме (r). В итоге получим коэффициент снижения пропускной способности: d=Rmax/R=f*r+(1-f)
где Rmax - максимальная пропускная способность (полная загрузка всех конвейеров), R - реальная пропускная способность, ![]() - отношение максимальной пропускной способности в векторном режиме к пропускной способности в скалярном режиме.
- отношение максимальной пропускной способности в векторном режиме к пропускной способности в скалярном режиме.
Как видно из рис. 4.1, снижение производительности может быть весьма значительным.

Рис.4.1 Коэффициент снижения производительности
Так, например, при f = 0,1 и r =50 реальная производительность меньше максимальной в 5,9 раза. Конкретные значения f и r варьируются в зависимости от системы и прикладной области.
4.2. Стартовое время конвейера
Максимальная пропускная способность конвейерной машины достигается при обработке длинных векторов, поскольку только в этом случае доля времени, затрачиваемого на начальном этапе (загрузка параметров, реконфигурация, ожидание первого результата), оказывается максимальной. Следовательно, пропускная способность R как функция длины вектора l определяется выражением:
![]()
где ts - время прохождения одной стадии конвейера, tstart - стартовое время конвейера.
Типичными для современных суперЭВМ являются следующие цифры: tstart = 1000нс, ts = 15нс. Из графика этой функции, приведенного на рис.4.2, видно, что при малых длинах векторов пропускная способность может быть значительно ниже максимальной. Таким образом, необходимо стремиться к тому, чтобы длина векторов была возможно большей, а стартовое время меньшим.

Рис.4.2. Пропускная способность, как функция длины вектора
Наличие стартового времени приводит к тому, что векторная обработка оказывается эффективней скалярной лишь начиная с некоторого порога длины векторов. Соответствующей количественной мерой может служить коэффициент ускорения вычислений как функция длины вектора, а именно:
![]()
где r - введенное ранее отношение максимальных пропускных способностей при векторном и скалярных режимах соответственно. Отсюда найдем приближенную пороговую длину вектора:
![]()
где tscalar - время выполнения скалярных операций.
4.3. Зависимости по данным.
Условием работы процессора в режиме пиковой производительности является одновременное исполнение нескольких команд, обеспечивающее постоянную занятость всех функциональных устройств. При наличии зависимостей по данным между командами, т.е. когда одна команда не может исполняться до завершения другой, это условие нарушается. Такого рода зависимость может существовать между любыми двумя командами. Примером двух зависимых векторных команд может служить следующий фрагмент:
![]()
![]()
В этом случае снижение производительности может быть предотвращено с помощью образования цепочек операций, когда исполнение данной векторной команды начинается сразу, как только образуются компоненты участвующих в ней векторных операндов (см. рис.4.3). Данный метод может применяться в большом числе практических случаев, однако не всегда.

Рис.4.3. Образование цепочки операций
Например, его нельзя использовать в следующем примере:
![]()
поскольку для начала исполнения второй команды необходимо вычислить скалярный результат первой.
4.4. Зависимости по управлению.
Данный тип зависимости существует двумя командами в ситуациях до тех пор, пока не завершится исполнение предыдущей команды, и остается неизвестным, какая из двух окажется следующей. Такая зависимость обычно порождается условными переходами и является одним из наиболее существенных отрицательно влияющих на производительность факторов в скалярных процессорах с опережающим просмотром. В векторных ЭВМ, где часть операторов цикла заменена векторными командами, влияние данного фактора несколько ослаблено, однако остается еще значительным.
При наличии зависимостей данного типа, когда команда, с которой начинается та или иная ветвь, остается неизвестной до тех пор, пока не завершится исполнение предыдущей команды и последовательность не прервется, в потери времени входит полный цикл обработки команды: вызов, декодирование и др. Для уменьшения этих потерь различные конструктивные средства: предварительный вызов начальных команд обеих ветвей, являющихся возможными продолжениями данной; использование нескольких командных буферов для хранения разных участков программ; хранение, задержанных ветвей в виде, позволяющем загрузить процессор сразу после завершения выбора ветви. Эти методы, разработаны для высокопроизводительных скалярных процессоров.
4.5. Реализация условных операторов.
Векторная команда как единое целое не может быть выполнена в ситуациях, когда вид операции над элементами вектора зависит от условия, как, например, в следующем фрагменте:
if ![]() then
then![]() else
else![]()
Один из возможных выходов состоит в том, чтобы выполнить все операции в скалярном режиме, однако, как мы видели раньше, это привело бы к резкому снижению производительности, Более перспективной альтернативой является использование для управления векторной операцией так называемого вектора режима. Это битовый вектор, содержащий такое же число элементов, как и каждый из векторов в управляемой операции. Управление в данном случае означает то, что операция выполняется только над теми элементами векторов, которым соответствует значение 1 в одноименных позициях вектора режима. Примером может служить следующая последовательность команд:
Безусловно описанный способ лучше, чем скалярный, однако и при нем все еще остаются факторы, снижающие производительность.
4.6. Нахождение команд вне буфера
Как уже отмечалось при рассмотрении базовой структуры процессора, для обеспечения высокой производительности необходимо заранее вызывать команды из памяти и помещать в специальный буфер. Наличие такого буфера позволяет считывать из памяти целые блоки следующих друг за другом команд. Если эти команды находятся в памяти, организованной по принципу чередования адресов, то такая выборка может осуществляться параллельно со всеми преимуществами, которые представляет многомодульная организация памяти.
4.7. Ограничения, связанные с локальной памятью.
Для поддержания высокой скорости конвейера арифметических операций операнды должны, интенсивно поступать из памяти. Это, в свою очередь, требует разделения памяти, на модули с возможностью одновременного доступа, а также включения буфером для операндов и результатов. Такой 6уфер сглаживает изменения пропускной способности тракта обмена данными между памятью и арифметическими устройствами, а также позволяет осуществлять выборку из памяти~ элементов векторов в порядке, отличающемся от того, который должен быть на входе обрабатывающих устройств. Это, как будет показано далее, существенно расширяет диапазон прикладных задач, которые могут эффективно решаться в векторном режиме. Буферная память служит также для хранения результатов, которые в последующих векторных командах выступают в качестве операндов.
По способу организации локальной памяти векторные процессоры делятся на два класса. К первому относятся те, в которых команды исполняются по принципу “регистр-регистр”, а ко второму - по принципу “память-память”. В первом случае локальная память представляет собой набор векторных регистров, адресуемых в командах, а во втором: локальную память, работающую как - буферное устройство и остающуюся невидимой для программиста. Основным преимуществом систем первого класса состоят в следующем: команды, в которых указаны короткие адреса регистров, имеют меньшую длину; промежуточные результаты естественным образом хранятся на регистрах; облегчается процесс контроля зависимостей между командами. Главный недостаток данного подхода связан с ограниченностью разрядности и числа регистров.
4.8. Ограничения, связанные с механизмом адресации и недостаточно эффективной пропускной способностью памяти.
Поскольку время доступа к памяти существенно превышает длительность одной стадии обрабатывающего конвейера, а в процессе исполнения программ требуются одновременные обращения к памяти за различными операндами, обеспечение адекватной пропускной способности памяти в векторном режиме, когда элементы векторов-операндов занимают последовательный ряд адресов достигается за счет организации памяти в виде нескольких модулей и применения принципа чередования адресов (интерливинг/расслоение). Это позволяет даже при максимальной пропускной способности осуществлять бесконфликтный доступ к блокам последовательно адресуемых элементов векторов.
4.9. Ограничения, связанные с конфликтами доступа к памяти.
К ограничивающим факторам относятся конфликты доступа, возникающие при одновременном появлении нескольких разных - о6ращений к памяти. Необходимым условием работы системы с максимальной производительностью является своевременное считывание команд из памяти, вызов скалярных и векторных операндов и запись зарабатываемых результатов. Указанные запросы реализуются через равные порты и “мешают” друг другу, что приводит к неполному использованию пропускной способности памяти. Для того чтобы отрицательное влияние этих конфликтов на общую производительность было минимальным, устройство управления доступом к памяти должно соответствующим образом планировать порядок обслуживания запросов.
Например, в системе Cray X-MP память разделена на четыре секции, каждая из которых имеет четыре порта: три обслуживают запросы процессоров и один обслуживает ввод/вывод. Порты А и В предназначены для чтения, а порт С для записи. Возникающие конфликты разрешаются с помощью системы приоритетов, причем последние зависят от вида обращения и времени поступления. Из сказанного ясно, что получить адекватную оценку производительности можно только путем прогонки программ на реальном оборудовании.
4.10. Ограничения, связанные со специализированными арифметическими устройствами.
Максимальная пропускная способность системы достигается только в том случае, когда все арифметические устройства используются полностью. Как было отмечено выше, полной загрузке этих устройств препятствует наличие зависимостей по данным и по управлению. Другим ограничивающим фактором уменьшающим эффективную производительность, является специализированность арифметических устройств, состоящих из устройства сложения, устройства умножения и т.д. В этом случае полное использование арифметического оборудования возможно только на специально подобранной смеси векторных и скалярных операций. Следовательно, реальная производительность зависит от состава операций в конкретной программе.
4.11. Ограничения, связанные с объемом памяти.
При решении многих прикладных задач массивы данных оказываются столь большими, что не могут уместиться в главной памяти. В этих случаях часть данных приходится хранить в памяти второго уровня и осуществлять подкачку и удаление информации в процессе счета. Размер главной памяти, скорость подкачки, способ сегментирования - все эти факторы оказывают значительное влияние на производительность.
5. ОЦЕНКА ОБЩЕЙ ПРОИЗВОДИТЕЛЬНОСТИ
Ввиду сложного характера взаимодействия между факторами, снижающими производительность, и зависимостью степени влияния этих факторов от конкретных программ оценка призводительности в целом должна осуществляться на специально подобранных прикладных задачах. Приближенная оценка может быть получена с помощью контрольных задач, состоящих из набора типовых тестовых программ. Проблема, связанная с такой приближенной оценкой, заключается в трудности определения термина <типовой>. Искусственные контрольные задачи, содержащие в нужном соотношении скалярные операции и векторные команды различных типов, могут дать лишь самые грубые оценки. Недостаток данного метода состоит в том, что он не учитывает взаимосвязи между командами, роль которых в формировании реального показателя производительности может быть значительной. Одними из наиболее широко используемых для оценки векторных машин контрольных задач являются так называемые Ливерморские циклы, разработанные в Национальной лаборатории им. Лоуренса в г. Ливерморе (США). Интересно отметить, что для всех типов машин оценки, полученные на разных циклах, сильно отличаются друг от друга. Например, согласно этим оценкам производительность Сrау-1 колеблется от 3 до 90 млн. операций с плавающей запятой в секунду. Кроме того, хотя наилучшие и наихудшие с точки зрения производительности циклы практически одни и те же для всех машин, характер зависимости производительности от типа цикла на разных машинах существенно отличается один от другого. Это подтверждает тезис о специфическом влиянии на производительность тех или иных особенностей организации систем. На производительность оказывает влияние также качество используемого компилятора.
- Супер ЭВМ. Аппаратная и программная организация / Под. ред. С. Фернбаха: Пер. с англ.- М.: Радио и связь, 1991. - 320 с.: ил.
